AI Speak : Search Engine Indexing
Step 1 : Web crawlers find and download documents.
After a user enters a search query, it is too late to go look at all the content available on the internet.1 The web docuements are looked at beforehand, and their content is broken down and stored in different slots. Once the query is available, all that needs to be done is to match what is in the query with what is in the slots.Web crawlers are pieces of code that find and download documents from the web. To start with, they are given a set of web site addresses (URLs) to access. This set is called the seed set. As they download a page from the seed, they look inside to see if there are links to new web pages. If yes, they add these new addresses to their to-do list. Then, they download and look inside the new pages for more links.
If the seed set is diverse enough, crawlers end up visiting every site that allows access to them. Since documents get updated, a crawler also has to go back and check already visited ones for updates and new links.
Step 2: The document gets transformed into multiple pieces
The document downloaded by the crawler may be a clearly structured web page (written in a language called html) with its own description of content, author, date etc. It can also be a badly scanned image of an old library book. Search engines can usually read a hundred different document types.1 They convert these into html or xml and store them in tables (called BigTable in the case of Google).A table is made up of smaller sections called tablets. Each row of the tablet is dedicated to one web page, with the web address uniquely identifying the row. These rows are arranged in some order which is recorded along with a log for updates. Each column has specific information related to the webpage which can help with matching the document content to the contents of a future query.The columns contain :
- The website address. Not only does it identify the row, the address itself can give a good description of the contents in the page. It can also identify if this is is a home page in which case the content will be representative of the entire website.
- Titles, headings and words in bold face that describe important content.
- Metadata of the page. This is information about the page that is not part of the main content, such as the document type (e.g., email or web page), document structure and other features such as document length. Html pages also have keywords in the description that are valuable. Scientific articles and newspaper articles have author and publishing date. Images and videos have their own metadata.
- Description of links from other pages to this page. When other pages link to a web page, they usually give descriptive text which is underlined to indicate the presence of the hyperlink. This text, called anchor text, is a good description of what that author things this page is about. Anchor text thus gets separate columns - more the links, more the columns used. The presence of links is also used for ranking, to determine how popular a web page is (Take a look at Google's Pagerank , a ranking system that uses links to and from a page to gauge quality and popularity).
- People’s names, company or organization names, locations, addresses time and date expressions, quantities and monetary values etc. Machine learning algorithms can be trained to find these entities in any content. Here, training data will have text annotated by a human being. The machine learns to tell what is the probability that the next word is an entity.1
One column of the table, perhaps the most important, contains the main content of the document. Since a webpage can have other information like external links and advertisements, the main content has to be identified first. One technique uses a machine learning model to “learn” which is the main content in any webpage. Like the model which learnt whether a card is from “Group A” or “Group B” in AI Speak : Machine Learning and the model which learnt which is a bicycle and which is a motorcycle in Hands on Machine Learning, the model here learns which content is important for search and which is not.
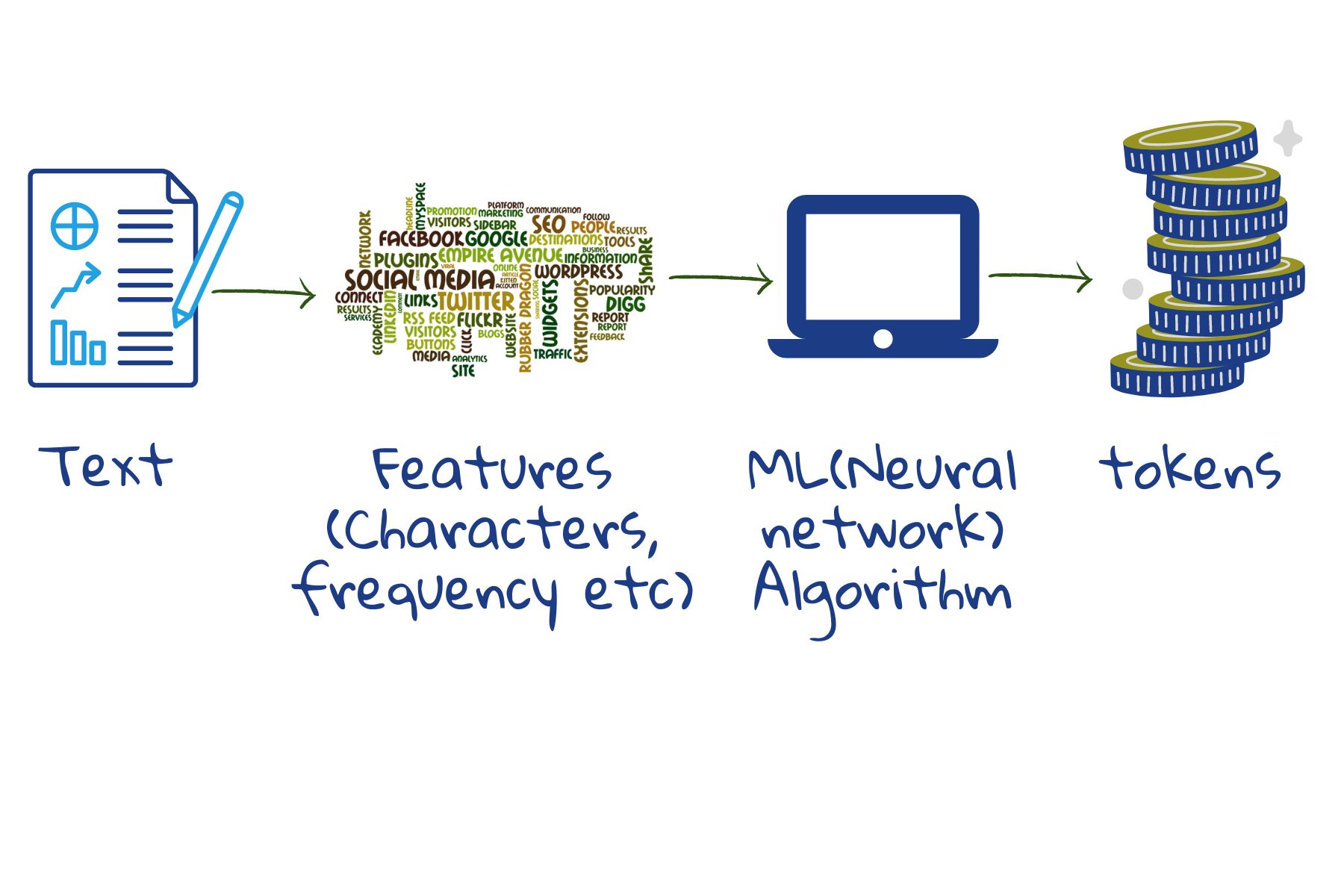
We can of course match exact words from the query to the words in a web document, like the Find button in any word processor. But this is not very effective as people use different words to talk about the same object. Just recording the seperate words will not help to capture how these words combine with each other to create meaning: It is ultimately the thought behind the words that help us communicate and not the words themselves. Therefore, all search engines transform the text in a way that makes it easier to match with the meaning of the query text. Later, the query is processed similarly.
As word parts, the total number of different tokens that need to be stored is reduced. Current models store about 30,000 to 50,000 tokens.2 Misspelled words can be identified because parts of them still match with the stored tokens. Unknown words may turn up search results, since their parts might match with the stored tokens.
Here, the training set for machine learning is made of example texts. Starting from individual characters, space and punctuation, the model merges characters that occur frequently to form new tokens. If the number of tokens is not high enough, it continues the merging process to cover bigger or less frequent word parts. This way, most of the words, word endings and all prefices can be covered. Thus given a new text, the machine can easily split it into tokens and send it to storage.
Step 3 : An Index is built for easy reference
Once the data is tucked away in BigTables, an index is created. At the end of a textbook,the index lists important terms and the page numbers where they can be found. Search index has the tokens in a web document and their location. Search engines may also add statistics to the index - how many times a token occurs in a document, how important is it for the document etc. Position information may also be recorded: Is the token in the title or a heading? Is it concentrated in one part or is it found throughout the document? Does one token always follow another? Or, all this can be given as a single score which can be used for ranking.
Nowadays, many search engines use a combination of traditional indexing and language based models generated by deep neural networks. The latter encodes semantic details of the text and is responsable for better understanding of queries.3 They help the search engines go beyond the query to capture the information need that induced the query.
These 3 steps give a simplified account of what is called "Indexing" - finding, preparing and storing documents and creating the index. What comes next are the steps involved in "Ranking" - matching query to content and displaying the results according to relevance.
------------------------------------------------------------------------------------------------------
1 Croft, B., Metzler D., Strohman, T., Search Engines, Information Retrieval in Practice, W.B. Croft, D. Metzler, T. Strohman, 2015
2 Sennrich,R., Haddow, B., and Alexandra Birch, A., Neural Machine Translation of Rare Words with Subword Units, In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany. Association for Computational Linguistics, 2016
3 Metzler, D., Tay, Y., Bahri, D., Najork, M., Rethinking Search: Making Domain Experts out of Dilettantes, SIGIR Forum 55, 1, Article 13, June 2021
_thumb.jpg){kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_thumb.jpg){kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}