Machine learns
1 2023-01-04T08:02:48+00:00 Jotsna Iyer 4f2bfb514a09301de0e5275ee45bf5db41479839 7 1 plain 2023-01-04T08:02:48+00:00 AI for Teachers, An Open Textbook Version 1 English Jotsna Iyer 4f2bfb514a09301de0e5275ee45bf5db41479839This page is referenced by:
-
1
2023-01-04T08:02:47+00:00
AI Speak : How Youtube Learns You Part 2
2
plain
2023-12-16T20:55:46+00:00
The Process
Across Google, deep neural networks are now being used for machine learning.2 Based on the video model, Youtube's neural network takes videos similar to the ones already watched by the user. Then it tries to predict the watch time of each new video for a given user model and ranks them based on the prediction. The idea is then to show the 10 to 20 videos (depending on the device) with top rankings.
The process is similar to the Machine Learning model we studied earlier. First, the machine takes features from user and video models given by the programmer. It learns from training data what weight to give each feature to predict watch time correctly. And then, once tested and found to be ok, it can start predicting and recommending.Training
During training, millions of both positive and negative examples are given to the system. A positive example is when a user clicked on a video and watched for a certain time. A negative example is when the user did not click on the video or did not watch for long.2
The network takes in the user features and video features discussed under the models section of How Youtube Learns You Part 1.It adjusts the importance given to each input feature by checking whether it predicted correctly the watch time for a given video and user.
There are approximately one billion parameters(weight of each feature) to be learned on hundreds of billions of examples.2The network might also learn to disregard certain features - give it zero importance. Thus the embedding or the model the algorithm creates can be very different from what the developers envisioned.Testing
Once the network has been trained, it is tested on already available data and adjusted. Apart from accuracy of prediction, the output of the system has to be tuned by the programmer based on several value judgements. Showing videos that are too similar to already watched videos will not be very engaging. What does it really mean for a recommendation to be good? How many similar videos to show and how much diversity to introduce - both with respect to the other videos and with respect to the user history. How many of the user's interests to cover? What type of recommendations lead to immediate satisfaction and which lead to long-term use?1,3 These are all important questions to consider.
After this testing, realtime evaluation of the recommendations is done. The total watch time per set of predicted videos is measured.2 Longer a user watches the recommended set of videos, the model is considered to be more successful. Note that just looking at how many videos were clicked is not good for evaluation. Youtube evaluates its recommenders based on how many recommended videos were watched for a substantial fraction of the video, session length, time until first long watch and the fraction of logged in users with recommendations.1Interface
Finally, on to how the recommendations are presented to the viewer : How many videos to show? Should the best recommendations be presented all at once, or some should be saved for later? 3 How to display thumbnails and video titles? What other information to show? What settings can the user control? 1 Answers to these determine how Youtube keeps two billion users hooked round the clock.
------------------------------------------------------------------------------------------------------
1 Davidson, J., Liebald, B., Liu, J., Nandy, P., Vleet, T., The Youtube Video Recommendation System, Proceedings of the 4th ACM Conference on Recommender Systems, Barcelona, 2010
2 Covington, P., Adams, J., Sargin, E., Deep neural networks for Youtube Recommendations, Proceedings of the 10th ACM Conference on Recommender Systems, ACM, New York, 2016
3 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021
4 Spinelli, L., and Crovella, M., How YouTube Leads Privacy-Seeking Users Away from Reliable Information, In Adjunct Publication of the 28th ACM Conference on User Modeling, Adaptation and Personalization (UMAP '20 Adjunct), Association for Computing Machinery, New York, 244–251, 2020 -
1
2023-01-04T08:02:47+00:00
AI Speak : How Adaptive Systems Learn the Learner Part 2
1
plain
2023-01-04T08:02:47+00:00
The Process
In recent years, Machine learning is used more and more in adaptive systems, either as the only technology or in conjunction with other approaches.2 Where used, the principle role of ML is creating and updating student models based on a set of features, including results from assessments and new data that is generated all along the process.1
For the outer loop, models are created with the help of training data, by assigning suitable weights features to help recommend effective learning content.2 (Also refer how machine learning works.) These models are used to regularly recommend new learning paths that reflect student progress and changing interests - like new recommendations in Youtube. In ML based ALS, the number of pathways can run to trillions.3
In the inside loop, Machine learning is used to give suitable feedback, spot errors, infer gaps in knowledge and assess mastery of Knowledge Units : While working on one activity, a student might make errors. ML can be used to predict what errors rise from which knowledge gap. If a step of the solution is correct, ML can be used to predict which knowledge units have been mastered successfully.2
Other techniques used in adaptive systems involve less automation and more explicitly written rules for making inferences.2 They demand a lot of programming time and extra effort to accurately capture all the critera that go into decision making. Further, the results cannot often be generalised from one domain to the next or from one problem to the next.
Tools that use ML use large sets of data on actual student performance and are able to create the most dynamic learning paths for students over time.1 Like for all ML applications, there is training and testing to be done before being put to use in classrooms.Pedagogical model
In the case of Youtube, we saw that there are a lot of value judgements on what makes a good recommendation - like how many user interests to cover in one set of recommendations, how many videos should be similar to already watched ones, how much new content to add for diversity (Refer How Youtube learns you part 2). ALS involves similar judgements on what it means to master a KU and how to get to that mastery : the pedagogy and daily experience of the learner.4
In the case of ALS, these judgements and guidance on how a learner is to progress should be based on proven pedagogical theories. These go into the pedagogical model, and along with the domain and learner models, helps the machine choose an appropriate set of activities.
Some of the questions answered in this model are : Should the student be presented a concept, an activity or a test next? At what difficulty level? How to evaluate the learning and provide feedback? Where is more scaffolding necessary? 5 (Scaffolds are support mechanisms that give guidance on concepts and procedure, the strategy used and on how to reflect, plan and monitor learning.) The pedagogical model dictates the breadth and depth of activities and even whether to continue within the ALS or get help from the teacher.3Interface
The recommendations are presented along with other data like learner progress, performance and goals. The key questions here are:- How to deliver the content?
- How much content to recommend in one go?
- What is assigned directly and what is recommended?
- What are the supporting resources?
- Is it possible to provide group activities?
- How much autonomy to permit?
- Can the student change their preferences?
- Can the teacher change the learning pathways?
- What data is shown to the teacher?
- Is the teacher in the loop?
Evaluation
When the ALS is put to use, most systems monitor their own performance against criteria set by the programmer. Like in any AI tool, data might be biased. Inferences drawn by the system can be imprecise. The student’s past data will become less and less relevant with time.6 Therefore, the teacher also has to monitor the system’s performance and provide learner guidance and corrective measures where necessary.
It is also the teachers and peers who have to provide inspiration and reveal alternative resources : Research in recommendation systems was shaped by commercial content providers and online retail companies for over a decade. Thus, the focus has been on reliably providing recommendations that produce results that can be promoted. “The surprising delight of an unexpected gem”7 and roads less travelled, that which can strongly inspire enduring learning, is not a strong point of machine based personalised learning.
------------------------------------------------------------------------------------------------------
1 EdSurge, Decoding Adaptive, Pearson, London, 2016
2 Chrysafiadi, K., Virvou, M., Student modeling approaches: A literature review for the last decade, Expert Systems with Applications, Elseiver, 2013
3 Essa, A., A possible future for next generation adaptive learning systems, Smart Learning Environments, 3, 16, 2016
4 Groff, J., Personalized Learning : The state of the field and future directions, Center for curriculum redesign, 2017.
5 Alkhatlan, A., Kalita, J.K., Intelligent Tutoring Systems: A Comprehensive Historical Survey with Recent Developments, International Journal of Computer Applications 181(43):1-20, March 2019
6 du Boulay, B., Poulovasillis, A., Holmes, W., Mavrikis, M., Artificial Intelligence And Big Data Technologies To Close The Achievement Gap, In: Luckin, Rose ed. Enhancing Learning and Teaching with Technology. London: UCL Institute of Education Press, pp. 256–28, 2018
7 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021
-
1
2023-01-04T08:02:47+00:00
AI Speak : Machine Learning
1
plain
2023-01-04T08:02:47+00:00
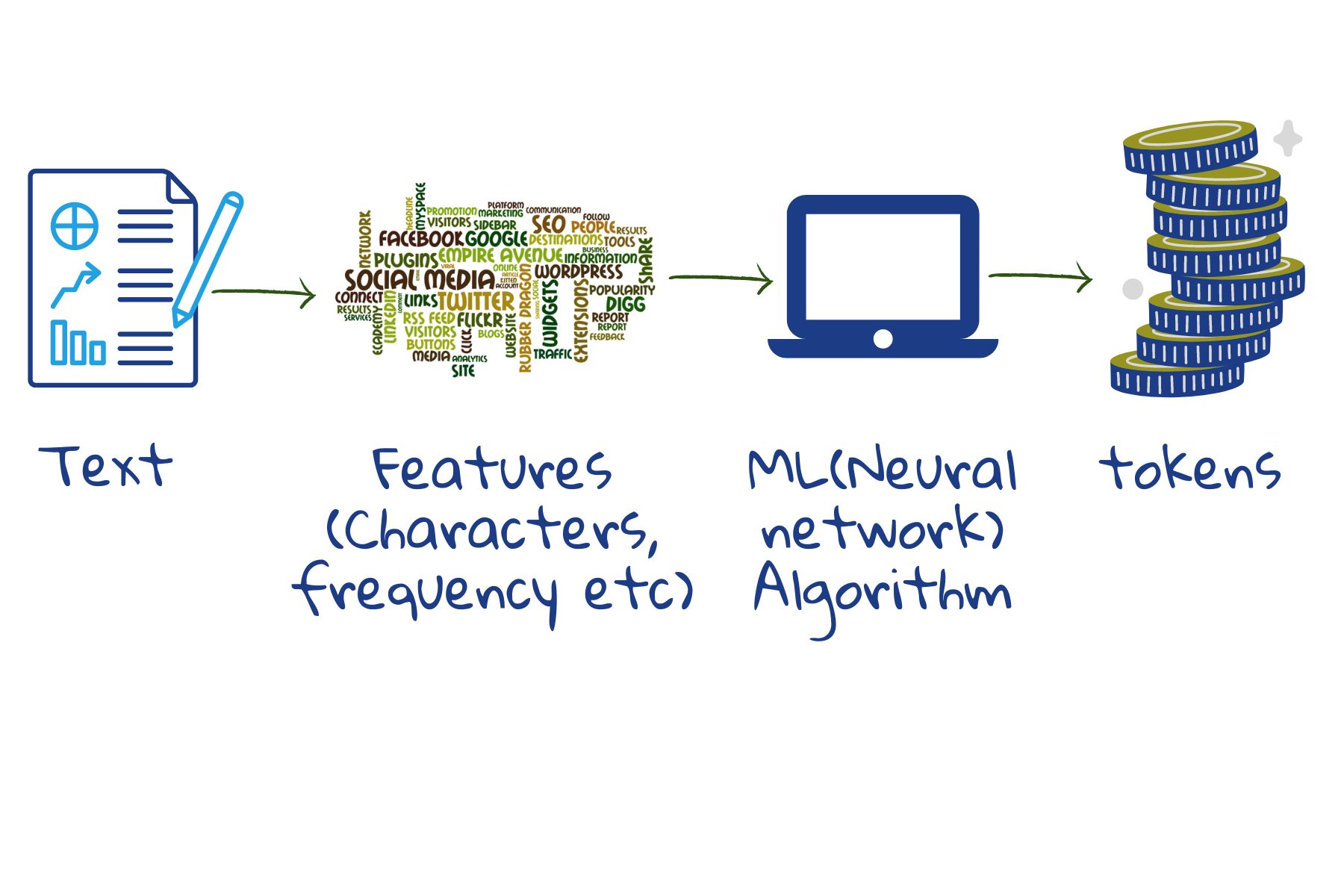
An algorithm is a fixed sequence of instructions for carrying out a task. It breaks down the task into easy, confusion-free steps : like a well written recipe.
Programming languages are languages that a computer can follow and execute. They act as a bridge between what we understand and what a machine can - ultimately, switches that go on and off. For a computer, images, videos, instructions are all 1s (switch is on) and 0s (switch is off).
When written in a programming language, an algorithm becomes a program. Applications are programs written for an end user.
Conventional programs take in data and follow the instructions to give an output. Many early AI programs were conventional. Since the instructions cannot adapt to the data, these programs were not very good at things like predicting based on incomplete information and Natural language processing (NLP).
A search engine is powered by both conventional and Machine learning algorithms. As opposed to conventional programs, ML algorithms analyse data for patterns and use these patterns or rules to make future decisions or predictions. That is, based on data - good and bad examples, they find their own recipe.
These algorithms are well suited for situations with a lot of complexity and missing data. They can also monitor their performance and use this feedback to become better with use.
This is not very different from humans, especially babies learning skills outside the conventional educational system. Babies observe, repeat, learn, test their learning and improve. Where necessary, they improvise.
But the similarity between machines and humans is very shallow. "Learning" from a human perspective is much different, and way more nuanced and complex than "learning" for the machine.A Classification Problem
One common task a ML application is used to perform is classification - Is this a photo of a dog or a cat? Is this student struggling or have they passed the exam? There are two or more groups. And the application has to classify new data into one of these groups.
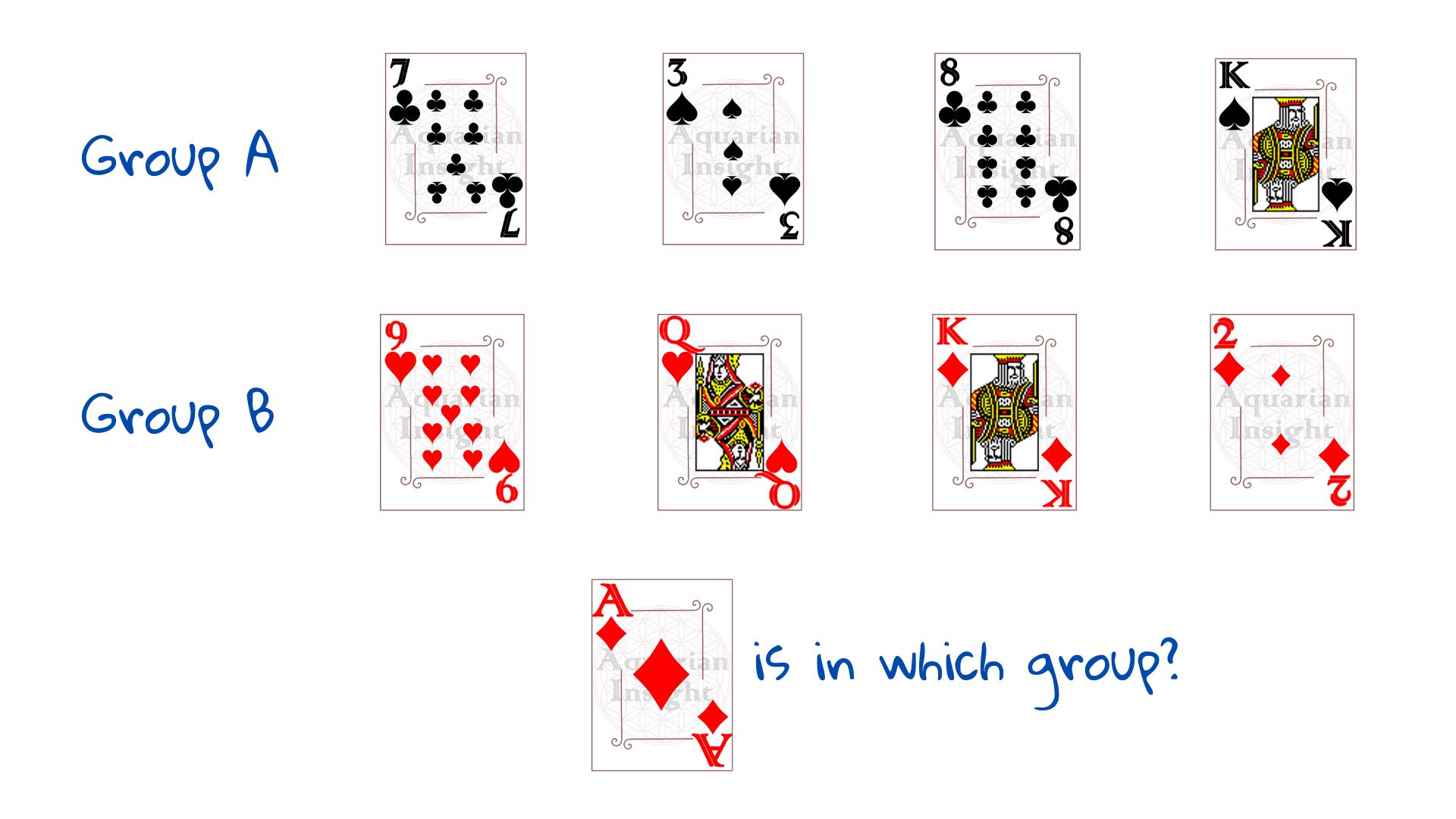
Let us take the example of a pack of playing cards divided into two piles - Group A and Group B, following some pattern. We need to classify a new card, the ace of diamonds as belonging to Group A or Group B.
First, we need to understand how the groups are split - we need examples. Let us draw four cards from Group A and four from Group B. These 8 example cases form our training set - data which helps us see the pattern - "training" us to see the result.
As soon as we are shown the arrangement to the right, most of us would guess that the Ace of diamonds belongs to Group B. We do not need instructions, human brain is a pattern finding marvel. How would a machine do this?
ML algorithms are built on powerful statistical theories. Different algorithms are based on different mathematical equations that have to be chosen carefully to fit the task at hand. It is the job of the programmer to choose the data, analyse what features of the data are relevant to the particular problem and choose the correct ML algorithm.The Importance of Data
The card draw above could have gone wrong in a number of ways. Please refer to the image. 1 has too few cards, no guess would be possible. 2 has more cards but all of the same suit - no way to know where diamonds would go. If the groups were not of the same size, 3 could very well mean that number cards are in group A and picture cards in group B.
Usually machine learning problems are more open ended and involve data sets much bigger than a pack of cards. Training sets have to be chosen with the help of statistical analysis or else errors creep in. Good data selection is crucial to a good ML application, more so than other types of programs. Machine learning needs a great number of relevant data. At an absolute minimum, a basic machine learning model should contain ten times as many data points as the total number of features.1That said, ML is also particularly equiped to handle noisy, messy and contradictory data.Feature Extraction
When shown Group A and Group B examples above, the first thing you might have noticed could be the colour of the cards. Then the number or letter and the suit. For an algorithm all these features have to be entered specifically. It cannot know what is important to the problem automatically.
While selecting the features of interest, programmers have to ask themselves many questions. How many features are too few to be useful? How many features are too many? Which features are relevant for the task? What is the relationship between the chosen features - is one feature dependent on the other? With the chosen features, is it possible for the output to be accurate?The Process
When the programmer is creating the application - they take data, extract features from it, choose an appropriate machine learning algorithm (mathematical function which defines the process), and train it using labeled data (in the case where the output is known - like Group A or Group B) so that the machine understand the pattern behind the problem.
For a machine understanding takes the form of a set of numbers - weights - that it assigns to each feature. With the correct assignment of weights, it can calculate the probability of a new card being in Group A or Group B. Typically, during the training stage, the programmer helps the machine by manually changing some values - this is called tuning the application.
Once this is done, the program has to be tested before putting in use. For this the labeled data that was not use for training would be given to the program. This is called the test data. The machine's performance in predicting the output would then be gauged. Once determined to be satisfactory, the program can be put to use : it is ready to take new data and make a decision or prediction about it.
The real time performance is then continuously monitored and improved (feature weights are adjusted to get better output). Often, real time performance gives different results than when ML is tested with already available data. Since experimenting with real users is expensive, takes high-effort, and often risky, algorithms are always tested using historic user data, which may not be able to assess impact on user behavior.1 This is why it is important to do a comprehensive evaluation of Machine Learning applications once in use :Feel like doing some hands on Machine Learning? Try this activity.
------------------------------------------------------------------------------------------------------
1Theobald, O. Machine Learning For Absolute Beginners: A Plain English Introduction (Second Edition) (Machine Learning From Scratch Book 1) (p. 24). Scatterplot Press. Kindle Edition.
2 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021
{kind=link}
.jpg){kind=link}
.jpg){kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
.jpg){kind=link}