Workinprogress
1 2023-01-04T08:02:48+00:00 Colin de la Higuera 674369ffe39c8de6fd174a82e7c7953f8456b348 7 1 "Work in progress" by futureshape is licensed under CC BY 2.0This page is referenced by:
-
1
2023-01-04T08:02:47+00:00
All that data : Personal identity, Bias and Fairness
3
plain
2023-06-15T09:07:09+00:00
This page is still being processed. Please come back later!
-
1
2023-01-04T08:02:47+00:00
Changing practices
1
How adaptive learning changes the classroom setup
plain
2023-01-04T08:02:47+00:00
This page is still being processed. Please come back later!
"Some of the most widespread education technologies
did not demand much change in teachers’ practices.
Digitized books were, after all, just books in a different
medium. PCs and Chromebooks provided an electronic
replacement for typewriters and paper and pencil, but
didn’t immediately revolutionize the classroom.
Adaptive learning does not fit easily
into the status quo. Besides having
to use a blended learning model, in
which class-time is divvied up between
traditional and electronic learning,
teachers must be willing to let
students progress at their own pace.
They need to be comfortable letting
software make real decisions about
what students should learn
next, and use quantitative data on
student performance gathered by
the software along with their own
qualitative gut instincts. They need to
be willing to trade the stand-in-thefront-
of-the-room-and-lecture model,
and instead provide more intimate,
personalized instruction to whichever
students aren’t on computers at that
given moment.
At Aspire ERES Academy in Oakland,
CA, students spend up to a quarter of
their day (50 to 80 minutes in total)
using online tools, including ST Math
and i-Ready. Like the Milpitas public
schools, Aspire Public Schools, which
operates 38 schools in California and
Tennessee, saw adaptive technology
as the most efficient way to achieve its
goal of college-readiness for students
in low-income populations. At ERES
Academy, 99 percent of the students
re English learners.
Besides the obvious logistical
challenges of a blended classroom,
such as setting up rotations for
students to cycle from teacher time
to computer time, using adaptive
learning tools requires other changes.
Every Friday, second-grade teacher
Mark Montero has 15 to 30 minute
“data talks,” when the students talk
about their progress and the problems
they ran into using the adaptive
products. Students who are doing
particularly well are named “student
coaches”. Montero makes a list of who
is struggling with what, and assigns
one of the coaches to spend the last
10 minutes of their 30 minute rotation
helping one of their classmates
overcome the hurdle. “Kids need to
discuss what they’re doing on the
computer,” he says.
Adaptive technology requires a
different sort of trust between teacher
and student. “You have to let go of
some of the micromanagement,”
says Montero." EdSurge, Decoding Adaptive, Pearson, London 2016
"For example, if a teacher uses curriculum with a strict pacing guide – outlining
every objective the teacher must teach each day of the school year with
frequent assessments and without flexibility or exceptions – incorporating
a tool with an adaptive sequence into the classroom will most likely be
unsuccessful. Tools with adaptive sequences allow students to work on any skill
at any time, the tool’s approach and the teacher’s approach are in conflict.
How an adaptive tool is implemented in a school must align with how the tool
was designed to be used, in order to be successful. For example, a tool with an
adaptive sequence must be used in a learning environment that supports:
• Students working at their own pace.
• Students working on different content.
• Students working on different skills that might be above or below the
grade-level expectations.
• Students working on skills in a unique order.
• Students working on skills that are different to the skills that are being
taught in the classroom at the same time
"EdSurge, Decoding Adaptive, Pearson, London 2016 -
1
2023-01-04T08:02:47+00:00
Different Intelligent Tutoring Systems
1
plain
2023-01-04T08:02:47+00:00
This page is still being processed. Please come back later!
Cognitive Tutors
is a type of Intelligent Tutoring System which uses Cognitive Science to model how a student thinks about and learns a subject. An example would be the Carnegie Cognitive Tutor.
Intelligent Tutoring Systems (ITS)
"a digital technology that provides immediate and customized instruction and feedback to learners, designed to simulate a human tutor’s behavior and guidance." Groff,J., Personalized Learning: The State of the Field & Future Directions, Center for Curriculum Redesign, 2017.
Natural Language ITS
"Dialog based ITSs have the same main goal as traditional ITSs, which is to increase the level
of engagement and learning gains. However, dialog based ITSs can use different dimensions of
evaluation in classifying learner’s responses, comprehending learner’s contributions, modeling
knowledge, and generating conversationally smooth tutorial dialogs. D’Mello and Graesser [113]
conducted a study to describe how dialog based ITSs can be evaluated along these dimensions
using AutoTutor as a case study." Alkhatlan, A., Kalita, J.K., Intelligent Tutoring Systems: A Comprehensive Historical
Survey with Recent Developments, International Journal of Computer Applications 181(43):1-20, March 2019
Spoken Dialog
"One advantage is in terms
of self-explanation, which gives the student a better opportunity to construct his/her knowledge
[115]. For instance, Hauptmann et al. showed that self-explanation happens more often in speech
than in typed interaction [116]. Another advantage is that speech interaction provides a more
accurate student model. Students use meta-communication strategies such as hedges, pauses, and
disfluencies, which allow the tutor to infer more information regarding student understanding. The
following will discuses some computer tutors, which implement spoken dialogue [114] [115].
ITSPOKE is an ITS which uses spoken dialogue for the purpose of providing spoken feedback and
correcting misconceptions [117]. The student and the system interact with each other in English
to discus the student’s answers. ITSPOKE uses a microphone as an input device for the student’s
speech and sends the signal to the Sphinx2 recognizer [118]. Litman et al. showed that ITSPOKE
is more effective than typed dialogue; however, there was no evidence that ITSPOKE increases
student learning [114]. In addition, it was clear that speech recognition errors did not decrease
learning."Alkhatlan, A., Kalita, J.K., Intelligent Tutoring Systems: A Comprehensive Historical
Survey with Recent Developments, International Journal of Computer Applications 181(43):1-20, March 2019
Affective Tutoring System
"Affective Tutoring Systems (ATS) are ITSs that can recognize human emotions (sad, happy, frustrated,
motivated, etc.) in different ways [119]. It is important to incorporate the emotions of
students in the learning process because recent learning theories have established a link between
emotions and learning, with the claim that cognition, motivation and emotion are the three components
of learning [120][121]. Over the last few years, there has been a great amount of interest in
computing the learner’s affective states in ITSs and studying how to respond to them in effective
ways [122].
Affective tutors use various techniques to enable computers to recognize, model, understand and
respond to students’ emotions in an effective manner. Knowing the emotional states of the student
provides information on the student’s psychological states and offers the possibility of responding
appropriately [119]. A system can embed devices to detect a student’s affective or emotional states.
These include PC cameras, PC microphones, special mouses, and neuro-headsets among others.
These devices are responsible for identifying physical signals such as facial image, voice, mouse
pressure, heart rate and stress level. These signals are then sent to the system to be processed.
Consequently, the emotional state is obtained in real time. The ATS objective is to change a negative
emotional state (e.g., confused) to a positive emotional state (e.g. committed) [72].
In [123], the learners’ affective states are detected by monitoring their gross body language (body
position and arousal) as they interact with the system. An automated body pressure measurement
system is also used to capture the learner’s pressure. The system detects six affective states of the learner: confusion, flow, delight, surprise, boredom and neutral. If the system realizes that the
student is bored, the tutor stimulates him by presenting engaging tasks. If frustration is detected,
the tutor offers encouraging statements or corrects information that the learner is experiencing
difficulty with. Experiments suggest that that boredom and flow might best be detected from body
language although the face plays a significant role in conveying confusion and delight.
Jraidi et al. present an ITS that acts differently when the student is frustrated [124]. For example,
it may provide problems similar to ones in which the student has been successful to help the student.
In case of boredom, the system provides an easier problem to motivate the student again or provides
a more difficult problem if the problem seems too easy. Another approach used in the system to
respond to student emotions integrates a virtual pedagogical agent called a learning companion
to allow affective real time interaction with the learners. This agent can communicate with the
learner as a study partner when solving problems, or provide encouragement and congratulatory
messages, appearing to care about the learner. In other words, these agents can provide empathic
responses which mirror the learner’s emotional states [72].
Wolf and his colleagues also implement an empathetic learning companion that reflects the last
expressed emotion of the learner as long as the emotion is not negative such as frustration or
boredom [125][126]. The companion responds in full sentences providing feedback with voice and
emotion. The presence of someone who appears to care can be motivating to the learners. Studies
show that students who use the learning companion increased their math understanding and level
of interest, and show reduced boredom. Another affective tutoring system that uses an empathetic
companion to respond to learner emotion is a system that practices interview questions with users
[127]. The system perceives the user’s emotion by measuring skin conductance and then takes
appropriate actions. For instance, the agent displays concern for a user who is aroused and has a
negatively valenced emotion, e.g., by saying “I am sorry that you seem to feel a bit bad about that
question”. Their study shows that users receiving feedback with empathy are less stressed when
asked interview questions."Alkhatlan, A., Kalita, J.K., Intelligent Tutoring Systems: A Comprehensive Historical
Survey with Recent Developments, International Journal of Computer Applications 181(43):1-20, March 2019"information can be used to enhance learning by means of nudges that movestudents out of negative states such as boredom or frustration that inhibit learninginto positive states such as engagement or enjoyment. Affective states can bedetected through computational analysis of data extracted from speech, facialexpressions, eye tracking, body language, physiological signals, or combinationsof these (D'Mello and Kory, 2015). In the iTalk2Learn system, for example, astudent’s affective state is determined through detection of keywords and prosodicfeatures in their speech as they talk aloud when interacting with the system(Grawemeyer et al., 2015b). Such detailed student modelling can enable affect aware support for the student, which has been shown to contribute to reducing boredom and off-task behavior, with promising effects on learning(Grawemeyer et al.,, in press). "du Boulay, Ben; Poulovasillis, Alexandra; Holmes, Wayne and Mavrikis, Manolis (2018). Artificial Intelligence And Big Data Technologies To Close The Achievement Gap. In: Luckin, Rose ed. Enhancing Learning and Teaching with Technology. London: UCL Institute of Education Press, pp. 256–285
"In his commentary of VanLehn’s review (2006) of ITS du Boulay (2006) noted that
the affective, motivational and metacognitive state of the student has only “fleetingly”
been addressed inmost learning systems. Traditional educational systems “have operated
largely at the cognitive level and have assumed that the learner is already able to manage
her own learning, is already in an appropriate affective state and also is already motivated
to learn” (du Boulay et al. 2010, p.197).
In recent years, recognizing the limitations of “cognition-only” approaches, researchers
have begun to model key aspects of students’ motivation, affect, and meta-cognition with
the aim of providing adaptive scaffolding for addressing differences in these areas (Desmarais
and Baker 2012)." Essa, A., A possible future for next generation adaptive learning systems, Smart Learning Environments, 3, 16, 2016Game-based Tutoring Systems
"The novelty of an ITS and its interactive components is quite engaging when they are used for
short periods of time (e.g., hours), but can be monotonous and even annoying when a student is required to interact with an ITS for weeks or months [132]. The underlying idea for game based
learning is that students learn better when they are having fun and engaged in the learning process.
Game based tutoring systems engage learners to interact actively with the system, thereby
making them more motivated to use the system for a longer time [133]. Whereas the ITS principles
maximize learning, the game technologies maximize motivation. Instead of learning a subject in
a conventional and traditional way, the students play an educational game which successfully
integrates game strategies with curriculum-based contents. Although there is no overwhelming
evidence supporting the effectiveness of educational game based systems over computer tutors,
it has been found that educational games have advantages over traditional tutoring approaches
[134][135]. Moreno and Mayer [136] summarize characteristics of educational games that make
them enjoyable to operate. These are interactivity, reflection, feedback, and guidance.
To enhance both engagement and learning, Rai and Beck implemented game-like elements in
their math tutor [137]. The system provides a math learning environment and the students engage
in a narrated visual story. Students help story characters solve the problem in order to move the
story forward as shown in Figure 4. Students receive feedback and bug messages as when using a
traditional tutor. The study found that students are more likely to interact with the version of the
math tutor that contains game-like elements; however, the authors suggest adding more tutorial
features to a game-like environment for higher levels of learning.
Another tutoring system that uses an educational game approach is Writing Pal (W-Pal), which
is designed to help students across multiple phases of the writing process [138]. Crystal Island is a
narrative-centered learning environment in biology, where students attempt to discover the identity
and source of an infectious disease on a remote island. The student (player) is involved in a scenario
of meeting a patient and attempts to perform a diagnosis. The study of educational impact using
a game based system by Lester at el. [139] found that students answer more questions correctly
on the post-test than the pre-test, and this finding was statistically significant. Additionally, there
was a strong relationship between learning outcomes, in-game problem solving and increased
engagement" -
1
2023-01-04T08:02:48+00:00
Cookies and fingerprinting
1
plain
2023-01-04T08:02:48+00:00
This page is still being processed. Please come back later!
Rewrite : small text files that a Web browser places on a user’s computer system for the purposes of tracking and recording that user’s activities on a Web site
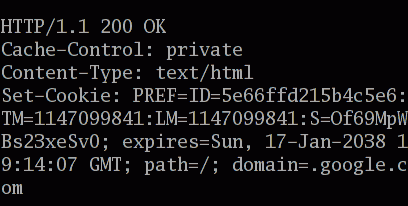
"Cookies technology is not only embedded in the design of contemporary Web browsers, it is also used by major search engine companies to acquire information about users. In so far as these companies place cookies on users’ computer systems, without first getting their consent, they also seem to contribute to, and perhaps even exacerbate, at least one kind of technology-related bias—i.e., one that threatens values such as privacy and autonomy, while favoring values associated with surveillance and monitoring. However, since this kind of bias also applies to design issues affecting Web browsers, it is not peculiar to search engines per se." Tavani, H., Zimmer, M., Search Engines and Ethics, The Stanford Encyclopedia of Philosophy, Fall 2020 Edition), Edward N. Zalta (ed.)
"1994 The HTTP cookie is developed.
In its development stages, web users could fully restrict what data cookies could collect. However, data privacy measures were quickly removed, and users lost the power to control cookie data before the technology became widespread." Kant, T., Identity, Advertising, and Algorithmic Targeting: Or How (Not) to Target Your “Ideal User.” MIT Case Studies in Social and Ethical Responsibilities of Computing, 2021
"1996 Ad networks (platforms that serve as brokers between groups of publishers and groups of advertisers) increasingly emerge, including Doubleclick (now owned by Google)."..."1998 Open Profiling Standard (OPS) is bought and rolled out by Microsoft. OPS could securely store and manage individuals’ personal information and credit card details, allowing user profiles to be exchanged between vendors." ... "2008
Behavioral targeting begins to be integrated into real-time bidding, marking a crucial shift away from media content toward user behavior as key to targeting." Kant, T., Identity, Advertising, and Algorithmic Targeting: Or How (Not) to Target Your “Ideal User.” MIT Case Studies in Social and Ethical Responsibilities of Computing, 2021
Cookies and Beyond
"Of course, there are benefits to having services algorithmically rendered “more relevant”: cookies streamline site visits by storing user details, autofilling technologies can quickly complete registration forms, and filtering systems manage otherwise unmanageable amounts of content, all while the data needed for such user benefits is doubly harnessed to make platform profits. Despite (or indeed because of) its monetizable qualities, targeting creates a host of stark ethical problems in relation to identity articulation, collective privacy, data bias, raced and gendered discrimination and socioeconomic inequality." Kant, T., Identity, Advertising, and Algorithmic Targeting: Or How (Not) to Target Your “Ideal User.” MIT Case Studies in Social and Ethical Responsibilities of Computing, 2021
"2020 Apple bans third-party cookies and Google pledges to do so by 2022, prompting debates on the so-called “cookie apocalypse.”
Though welcomed by privacy-concerned users, third-party marketing companies such as Criteo experience a fall in share values and argue that the erasure of third-party cookies gives even more power to monopolistic first-party data trackers" Kant, T., Identity, Advertising, and Algorithmic Targeting: Or How (Not) to Target Your “Ideal User.” MIT Case Studies in Social and Ethical Responsibilities of Computing, 2021
"The HTTP cookie is “a way of storing information on the user’s computer about a transaction between a user and a server that can be retrieved at a later date by the server.” Cookie tracking works by storing this text file on a user’s computer and sending it to either third- or first-party cookie trackers, who then use this data to attribute characteristics to the user in the form of demographic profiling and other profiling mechanisms. It is important to note that cookies ultimately only capture information that is decipherable through abstracted correlation and “pattern recognition.” These abstract identifiers are then translated back into marketing demographic profiles by data brokers: computational referents of correlational and networked positionality are converted into “man,” “woman,” and so on by complex pre- and post-cookie data categorizations. It is the rendering of cookie data into “traditional social parameters” that makes cookie tracking so common and profitable."Kant, T., Identity, Advertising, and Algorithmic Targeting: Or How (Not) to Target Your “Ideal User.” MIT Case Studies in Social and Ethical Responsibilities of Computing, 2021
"Cookieless tracking refers to identifying and anticipating users through technologies alternative to the HTTP cookie. Common types of tracking have included Flash and canvas “fingerprinting,” which are seen as preferential to cookie tracking since fewer web users are aware of these technologies and they cannot be easily deleted. Third-party cookie aggregation is set to be banned by Google and other platforms by 2022. This is partially in response to privacy concerns: however, as the Electronic Frontier Foundation notes, Google is essentially replacing third-party cookie tracking with a new experimental tracking system that still works by “sorting their users into groups based on behavior, then sharing group labels with third-party trackers and advertisers around the web,” but in ways that users cannot necessarily know about or consent to.
" Kant, T., Identity, Advertising, and Algorithmic Targeting: Or How (Not) to Target Your “Ideal User.” MIT Case Studies in Social and Ethical Responsibilities of Computing, 2021
The easiest and most common method that Web developers use to passively collect user data is through cookies, which are relatively small files that store user-specific information such as preferences, account information, recent site activity, and the contents of a shopping cart. Your browser
Spencer, Stephan. Google Power Search: The Essential Guide to Finding Anything Online With Google (pp. 111-112). Koshkonong. Kindle Edition.
"More recently,
Libert studied third-party HTTP requests on the top 1 mil-
lion sites [31], providing view of tracking across the web. In
this study, Libert showed that Google can track users across
nearly 80% of sites through its various third-party domains.
Web tracking has expanded from simple HTTP cookies to
include more persistent tracking techniques. Soltani et al.
rst examined the use of
ash cookies to \respawn" or re-
instantiate HTTP cookies [53], and Ayenson et al. showed
how sites were using cache E-Tags and HTML5 localStor-
age for the same purpose [6]. These discoveries led to media
backlash [36, 30] and legal settlements [51, 10]. ............................
Device ngerprinting is a persistent tracking technique
which does not require a tracker to set any state in the user's browser. Instead, trackers attempt to identify users by a
combination of the device's properties." Englehardt, S., Narayanan, A., Online Tracking: A 1-million-site Measurement and Analysis, Extended version of paper at ACM CCS 2016, https://webtransparency.cs.princeton.edu/webcensus/
"the tool is less e ective for obscure trackers
(prominence < 0:1). In Section 6.6, we show that less prominent ngerprinting scripts are not blocked as frequently by
blocking tools. This makes sense given that the block list
is manually compiled and the developers are less likely to
have encountered obscure trackers." Englehardt, S., Narayanan, A., Online Tracking: A 1-million-site Measurement and Analysis, Extended version of paper at ACM CCS 2016, https://webtransparency.cs.princeton.edu/webcensus/
"Cookie syncing, a workaround to the Same-Origin Policy,
allows di erent trackers to share user identi ers with each
other. Besides being hard to detect, cookie syncing enables
back-end server-to-server data merges hidden from public
view, which makes it a privacy concern.............Most third parties are involved in cookie syncing.
.............
More interestingly, we find that the vast majority of top
third parties sync cookies with at least one other party: 45
of the top 50, 85 of the top 100, 157 of the top 200, and
460 of the top 1,000. This adds further evidence that cookie
syncing is an under-researched privacy concern." Englehardt, S., Narayanan, A., Online Tracking: A 1-million-site Measurement and Analysis, Extended version of paper at ACM CCS 2016, https://webtransparency.cs.princeton.edu/webcensus/
"Canvas Fingerprinting
Privacy threat. The HTML Canvas allows web appli-
cation to draw graphics in real time, with functions to sup-
port drawing shapes, arcs, and text to a custom canvas el-
ement. In 2012 Mowery and Schacham demonstrated how
the HTML Canvas could be used to ngerprint devices [37].
Di erences in font rendering, smoothing, anti-aliasing, as
well as other device features cause devices to draw the im-
age di erently. This allows the resulting pixels to be used
as part of a device ngerprint....Comparing our results with a 2014 study [1], we nd three
important trends. First, the most prominent trackers have
by-and-large stopped using it, suggesting that the public
backlash following that study was e ective. Second, the
overall number of domains employing it has increased con-
siderably, indicating that knowledge of the technique has
spread and that more obscure trackers are less concerned
about public perception. As the technique evolves, the im-
ages used have increased in variety and complexity, as we de-
tail in Figure 12 in the Appendix. Third, the use has shifted
from behavioral tracking to fraud detection, in line with the
ad industry's self-regulatory norm regarding acceptable uses
of ngerprinting.
6.2 Canvas Font Fingerprinting
Privacy threat. The browser's font list is very useful
for device ngerprinting [12]. The ability to recover the list
of fonts through Javascript or Flash is known, and existing
tools aim to protect the user against scripts that do that [41,
2]. But can fonts be enumerated using the Canvas interface?
"Englehardt, S., Narayanan, A., Online Tracking: A 1-million-site Measurement and Analysis, Extended version of paper at ACM CCS 2016, https://webtransparency.cs.princeton.edu/webcensus/
"WebRTC-based fingerprinting
Privacy threat. WebRTC is a framework for peer-to-
peer Real Time Communication in the browser, and acces-
sible via Javascript. To discover the best network path be-
tween peers, each peer collects all available candidate ad-
dresses, including addresses from the local network inter-
faces (such as ethernet or WiFi) and addresses from the
public side of the NAT and makes them available to the
web application without explicit permission from the user.
This has led to serious privacy concerns: users behind a
proxy or VPN can have their ISP's public IP address ex-
posed [59]. We focus on a slightly di erent privacy concern:
users behind a NAT can have their local IP address revealed,
which can be used as an identi er for tracking."Englehardt, S., Narayanan, A., Online Tracking: A 1-million-site Measurement and Analysis, Extended version of paper at ACM CCS 2016, https://webtransparency.cs.princeton.edu/webcensus/
"AudioContext Fingerprinting
The scale of our data gives us a new way to systemati-
cally identify new types of ngerprinting not previously re-
ported in the literature. The key insight is that ngerprint-
ing techniques typically aren't used in isolation but rather
in conjunction with each other. ..................;This is conceptually similar to canvas ngerprinting: audio
signals processed on di erent machines or browsers may have
slight di erences due to hardware or software di erences be-
tween the machines, while the same combination of machine
and browser will produce the same output."Englehardt, S., Narayanan, A., Online Tracking: A 1-million-site Measurement and Analysis, Extended version of paper at ACM CCS 2016, https://webtransparency.cs.princeton.edu/webcensus/
"Battery API Fingerprinting
As a second example of bootstrapping, we analyze the
Battery Status API, which allows a site to query the browser for the current battery level or charging status of a host
device. Olejnik et al. provide evidence that the Battery
API can be used for tracking [43]. The authors show how
the battery charge level and discharge time have a sucient
number of states and lifespan to be used as a short-term
identi er. These status readouts can help identify users who
take action to protect their privacy while already on a site.
For example, the readout may remain constant when a user
clears cookies, switches to private browsing mode, or opens
a new browser before re-visiting the site. We discovered two
ngerprinting scripts utilizing the API during our manual
analysis of other ngerprinting techniques.The second script, http://js.ad-score.com/
score.min.js, queries all properties of the BatteryManager
interface, retrieving the current charging status, the charge
level, and the time remaining to discharge or recharge. As
with the previous script, these features are combined with
other identifying features used to ngerprint a device."Englehardt, S., Narayanan, A., Online Tracking: A 1-million-site Measurement and Analysis, Extended version of paper at ACM CCS 2016, https://webtransparency.cs.princeton.edu/webcensus/
Goliath : Cookies weren’t intended to be surveillance devices; rather,
they were designed to make surfing the web easier. Websites
don’t inherently remember you from visit to visit or even from
click to click. Cookies provide the solution to this problem. Each
cookie contains a unique number that allows the site to identify
you. So now when you click around on an Internet merchant’s
site, you keep telling it, “I’m customer #608431.” This allows the
site to find your account, keep your shopping cart attached to you,
remember you the next time you visit, and so on.
Companies quickly realized that they could set their own
cookies on pages belonging to other sites—with their permission
and by paying for the privilege—and the third-party cookie was
born. Enterprises like DoubleClick (purchased by Google in 2007)
started tracking web users across many different sites. This is
when ads started following you around the web. "
Goliath : "Today, Internet surveillance is far more insistent than cookies.
In fact, there’s a minor arms race going on. Your browser—yes,
even Google Chrome—has extensive controls to block or delete
cookies, and many people enable those features. DoNotTrackMe is
one of the most popular browser plug-ins. The Internet
surveillance industry has responded with “flash cookies”—
basically, cookie-like files that are stored with Adobe’s Flash player
and remain when browsers delete their cookies. To block those,
you can install FlashBlock.
But there are other ways to uniquely track you, with esoteric
names like evercookies, canvas fingerprinting, and cookie
synching. It’s not just marketers; in 2014, researchers found that
the White House website used evercookies, in violation of its own
privacy policy. I’ll give some advice about blocking web
surveillance in Chapter 15.
Cookies are inherently anonymous, but companies are
increasingly able to correlate them with other information that
positively identifies us. " -
1
2023-01-04T08:02:48+00:00
Old translators
1
This was the stub on Dec 6th
plain
2023-01-04T08:02:48+00:00
This page is still being processed. Please come back later!
Translation is not the right way to learn a language: all experts will tell us that this could have been the way a long time ago, but modern didactics don't recommend it anymore.
Nevertheless, if you can translate, you can get around having to learn the language altogether for most practical situations.
Translation tools
Two translation tools exist and can easily be used online (Google translate, deepl)
Furthermore, it is now possible to use translation tools embedded inside the software to obtain rapidly a translation of a document respecting the original presentation.
Translation in education
Automatic translation tools can be used as soon as one has access to the internet. The adults use it in the context of work, so, unsurprisingly, the pupils learn how to use these tools as soon as they start learning languages.
Teachers will of course
------------------------------------------------------------------------------------------------------
"Translate This Page The Translate this page link only appears in search results next to pages that are in a foreign language and have no alternate version for the language you’ve specified in your search settings. When you click on it, Google will use its translation engine to convert the page text to your language. It’s rarely perfect—it struggles with idiomatic phrases and bad grammar in the source content—but you can usually get the gist of it.
Spencer, Stephan. Google Power Search: The Essential Guide to Finding Anything Online With Google (p. 25). Koshkonong. Kindle Edition. " -
1
2023-01-04T08:02:48+00:00
Similarities in life and distances in data
1
Wonder how a machine that only understands numbers can discover similarities in student behaviour?
plain
2023-01-04T08:02:48+00:00
This page is still being processed. Please come back later!
Ethical guidelines on the use of artificial intelligence and data in teaching and learning for educators, European Commission, October 2022 AI-supported
collaborative learning :
Data on each learner’s work style and past performance is used to divide them into groups
with the same ability levels or suitable mix of abilities and talents. AI systems provide
inputs/suggestions on how a group is working together by monitoring the level of interaction
between group members.
Similarities in life, distances in data
MIT : "The most common
type of unsupervised learning is cluster analysis, where the
algorithm looks for clusters of instances that are more similar
to each other than they are to other instances in the
data. These clustering algorithms often begin by guessing
a set of clusters and then iteratively updating the clusters
(dropping instances from one cluster and adding them to
another) so as to increase both the within-cluster similarity
and the diversity across clusters.
A challenge for clustering is figuring out how to measure
similarity. If all the attributes in a data set are numeric
and have similar ranges, then it probably makes sense just
to calculate the Euclidean distance (better known as the
straight-line distance) between the instances (or rows).
Rows that are close together in the Euclidean space are
then treated as similar. A number of factors, however, can
make the calculation of similarity between rows complex.
In some data sets, different numeric attributes have different
ranges, with the result that a variation in row values
in one attribute may not be as significant as a variation of
a similar magnitude in another attribute. In these cases,
the attributes should be normalized so that they all have
the same range. Another complicating factor in calculating
similarity is that things can be deemed similar in many
different ways. Some attributes are sometimes more important
than other attributes, so it might make sense to weight some attributes in the distance calculations, or it
may be that the data set includes nonnumeric data. These
more complex scenarios may require the design of bespoke
similarity metrics for the clustering algorithm to use."...... "is.
An unsupervised clustering algorithm will look for
groups of rows that are more similar to each other than
they are to the other rows in the data. Each of these groups
of similar rows defines a cluster of similar instances. For
instance, an algorithm can identify causes of a disease or
disease comorbidities (diseases that occur together) by
looking for attribute values that are relatively frequent
within a cluster. The simple idea of looking for clusters of
similar rows is very powerful and has applications across
many areas of life. Another application of clustering rows
is making product recommendations to customers. If a
customer liked a book, song, or movie, then he may enjoy
another book, song, or movie from the same cluster."
video
MIT: "The standard data science approach to this type of
analysis is to frame the problem as a clustering task. Clustering
involves sorting the instances in a data set into subgroups containing similar instances. Usually clustering
requires an analyst to first decide on the number of subgroups
she would like identified in the data. This decision
may be based on domain knowledge or informed by project
goals. A clustering algorithm is then run on the data
with the desired number of subgroups input as one of the
algorithms parameters. The algorithm then creates that
number of subgroups by grouping instances based on the
similarity of their attribute values. Once the algorithm has
created the clusters, a human domain expert reviews the
clusters to interpret whether they are meaningful. In the
context of designing a marketing campaign, this review
involves checking whether the groups reflect sensible customer
personas or identifies new personas not previously
considered.....As is true of all data science projects, one of the biggest
challenges with clustering is to decide which attributes to
include and which to exclude so as to get the best results.............One of the advantages of clustering as an analytics
approach is that it can be applied to most types of data.
Because of its versatility, clustering is often used as a dataexploration
tool during the data-understanding stage of
many data science projects. Also, clustering is also useful
across a wide range of domains. For example, it has been
used to analyze students in a given course in order to identify
groups of students who need extra support or prefer
160 Chapter 5
different learning approaches. It has also been used to
identify groups of similar documents in a corpus, and in
science it has been used in bio-informatics to analyze gene
sequences in microarray analysis."
"How do we operationalize diversity in a selection task? If we had a distance
function between pairs of candidates, we could measure the average distance
between selected candidates. As a strawman, let’s say we use the Euclidean
distance based on the GPA and interview score. If we incorporated such a diversity
criterion into the objective function, it would result in a model where the GPA is
weighted less. This technique has the advantage of being blind: we didn’t explicitly
consider the group membership, but as a side-effect of insisting on diversity of
the other observable attributes, we have also improved demographic diversity.
However, a careless application of such an intervention can easily go wrong: for
example, the model might give weight to attributes that are completely irrelevant
to the task.
More generally, there are many possible algorithmic interventions beyond
picking different thresholds for different groups. In particular, the idea of a
similarity function between pairs of individuals is a powerful one, and we’ll see
other interventions that make use of it. But coming up with a suitable similarity
function in practice isn’t easy: it may not be clear which attributes are relevant,
how to weight them, and how to deal with correlations between attributes" FML
{kind=link}
{kind=link}