ML Process
1 2023-01-04T08:48:01+00:00 Jotsna Iyer 4f2bfb514a09301de0e5275ee45bf5db41479839 10 1 plain 2023-01-04T08:48:01+00:00 AI for Teachers, An Open Textbook Version 1 English Jotsna Iyer 4f2bfb514a09301de0e5275ee45bf5db41479839This page is referenced by:
-
1
2023-01-04T08:48:00+00:00
AI Speak: Maschinelles Lernen
9
plain
2023-12-28T09:24:01+00:00
Ein Algorithmus ist eine feste Abfolge von Anweisungen zur Ausführung einer Aufgabe. Er zerlegt die Aufgabe in einfache, verwirrungsfreie Schritte: wie ein gut geschriebenes Rezept.
Programmiersprachen sind Sprachen, die ein Computer befolgen und ausführen kann. Sie dienen als Brücke zwischen dem, was wir verstehen, und dem, was eine Maschine kann - letztlich Schalter, die man ein- und ausschalten kann. Für einen Computer sind Bilder, Videos und Anweisungen alles Einsen ("Schalter ist an") und Nullen ("Schalter ist aus").
In einer Programmiersprache geschrieben, wird ein Algorithmus zu einem Programm. Anwendungen sind Programme, die für Endnutzende geschrieben werden.
Herkömmliche Programme nehmen Daten auf und folgen den Anweisungen, um eine Ausgabe zu erzeugen. Viele frühe KI-Programme waren konventionell. Da sich die Anweisungen nicht an die Daten anpassen können, waren diese Programme nicht sehr gut darin, Vorhersagen auf der Grundlage unvollständiger Informationen zu treffen und natürliche Sprache zu verarbeiten (Natural Language Processing, NLP).
Eine Suchmaschine wird sowohl von herkömmlichen als auch von maschinellen (ML) Lernalgorithmen angetrieben. Im Gegensatz zu herkömmlichen Programmen analysieren ML-Algorithmen Daten auf Muster und verwenden diese Muster oder Regeln, um zukünftige Entscheidungen oder Vorhersagen zu treffen. Das heißt, auf der Grundlage von Daten - guten und schlechten Beispielen - finden sie ihr eigenes "Rezept".
Diese Algorithmen eignen sich gut für Situationen mit hoher Komplexität und fehlenden Daten. Sie können auch ihre Leistung überwachen und dieses Feedback nutzen, um sich mit der Zeit zu verbessern.
Es ist nicht viel anders als bei Menschen, insbesondere bei Babys, die sich Fähigkeiten außerhalb des traditionellen Bildungssystems aneignen. Babys beobachten, wiederholen, lernen, testen und verbessern sich. Wenn nötig, improvisieren sie.
Aber die Ähnlichkeit zwischen Maschinen und Menschen ist sehr oberflächlich. „Lernen" aus menschlicher Sicht ist etwas ganz anderes und viel nuancierter und komplexer als „Lernen" für die Maschine.Ein Klassifizierungsproblem
Eine häufige Aufgabe, für die eine ML-Anwendung eingesetzt wird, ist die Klassifizierung: Handelt es sich um ein Foto eines Hundes oder einer Katze? Hat der Lernende Schwierigkeiten oder hat er/sie die Prüfung bestanden? Es gibt zwei oder mehr Kategorien. Und die Anwendung muss neue Daten in eine dieser Gruppen einordnen.
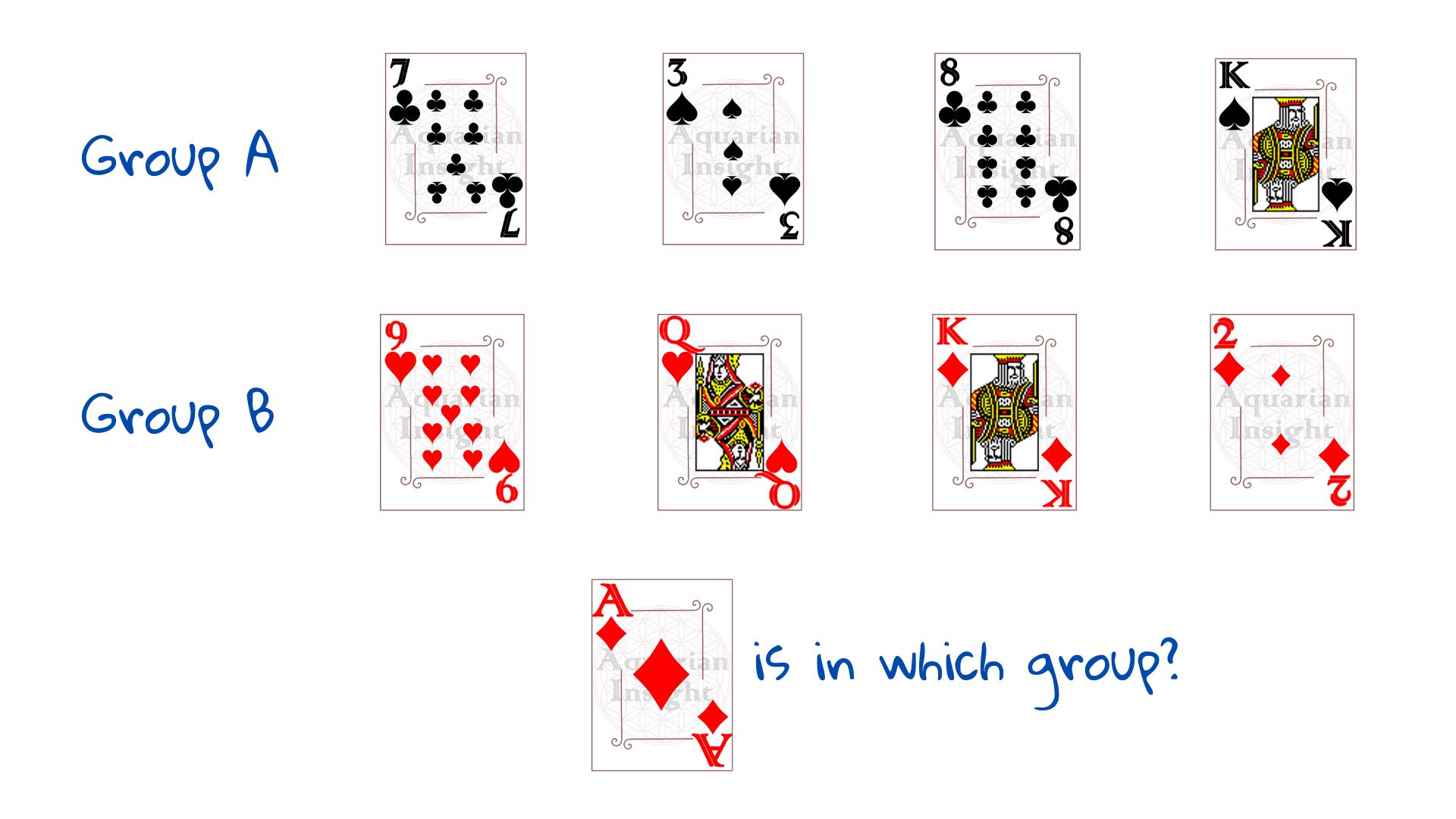
Nehmen wir das Beispiel eines Spielkartenstapels, der nach einem bestimmten Muster in zwei Stapel - Gruppe A und Gruppe B - unterteilt ist. Wir sollen eine neue Karte, das Karo-Ass, der Gruppe A oder der Gruppe B zuordnen.
Zunächst müssen wir verstehen, wie die Gruppen aufgeteilt sind - wir brauchen Beispiele. Ziehen wir vier Karten aus Gruppe A und vier aus Gruppe B. Diese 8 Beispielfälle bilden unsere Trainingsmenge, d.h. Daten, die uns helfen, das Muster zu erkennen. Wir „trainieren", das Ergebnis zu sehen.
Sobald uns die Anordnung auf der rechten Seite gezeigt wird, würden die meisten von uns erraten, dass das Karo-Ass zu Gruppe B gehört. Wir brauchen keine Anweisungen, das menschliche Gehirn ist ein Wunderwerk der Musterfindung. Wie würde eine Maschine dies tun?
Die Algorithmen des maschinellen Lernens beruhen auf leistungsstarken statistischen Theorien. Die verschiedenen Algorithmen beruhen auf unterschiedlichen mathematischen Gleichungen, die sorgfältig ausgewählt werden müssen, um der jeweiligen Aufgabe gerecht zu werden. Es ist die Aufgabe der programmierenden Person, die Daten auszuwählen, zu analysieren, welche Merkmale der Daten für das jeweilige Problem relevant sind, und den richtigen Algorithmus auszuwählen.Die Wichtigkeit von Daten
Die obige Kartenziehung hätte auf verschiedene Weise schiefgehen können. Bitte sehen Sie sich das Bild an. 1 hat zu wenige Karten, eine Vermutung wäre nicht möglich. 2 hat mehr Karten, aber alle von der gleichen Farbe, daher bietet es keine Ansatzpunkte um herauszufinden, wo Karo hinkommen würde. Wenn die Gruppen nicht gleich groß sind, könnte 3 sehr wohl bedeuten, dass die Zahlenkarten in Gruppe A und die Bildkarten in Gruppe B sind.
Im Allgemeinen sind die Probleme des maschinellen Lernens offener und umfassen Datensätze, die viel größer sind als ein Kartenspiel. Die Trainingsdatensätze müssen mit Hilfe einer statistischen Analyse ausgewählt werden, da sich sonst Fehler einschleichen. Eine gute Datenauswahl ist entscheidend für eine gute ML-Anwendung, mehr noch als bei anderen Programmtypen. Maschinelles Lernen benötigt eine große Anzahl relevanter Daten. Als absolutes Minimum sollte ein grundlegendes Modell für maschinelles Lernen zehnmal so viele Datenpunkte enthalten wie die Gesamtzahl der Merkmale.1 Darüber hinaus ist ML besonders gut geeignet, um mit "verrauschten", unklaren und widersprüchlichen Daten umzugehen.Extraktion von Merkmalen
Bei den oben gezeigten Beispielen für Gruppe A und Gruppe B ist Ihnen vielleicht als Erstes die Farbe der Karten aufgefallen. Dann die Nummer oder den Buchstaben und die Farbe. Für einen Algorithmus müssen alle diese Merkmale speziell eingegeben werden. Er kann nicht automatisch wissen, was für das Problem wichtig ist.
Bei der Auswahl der Merkmale, die von Interesse sind, müssen sich Programmiernde viele Fragen stellen. Wie viele Merkmale sind zu wenig, um nützlich zu sein? Wie viele Funktionen sind zu viele? Welche Merkmale sind für die Aufgabe relevant? In welchem Verhältnis stehen die ausgewählten Funktionen zueinander - ist eine Funktion von der anderen abhängig? Ist es mit den gewählten Merkmalen möglich, dass die Ausgabe genau ist?Der Prozess
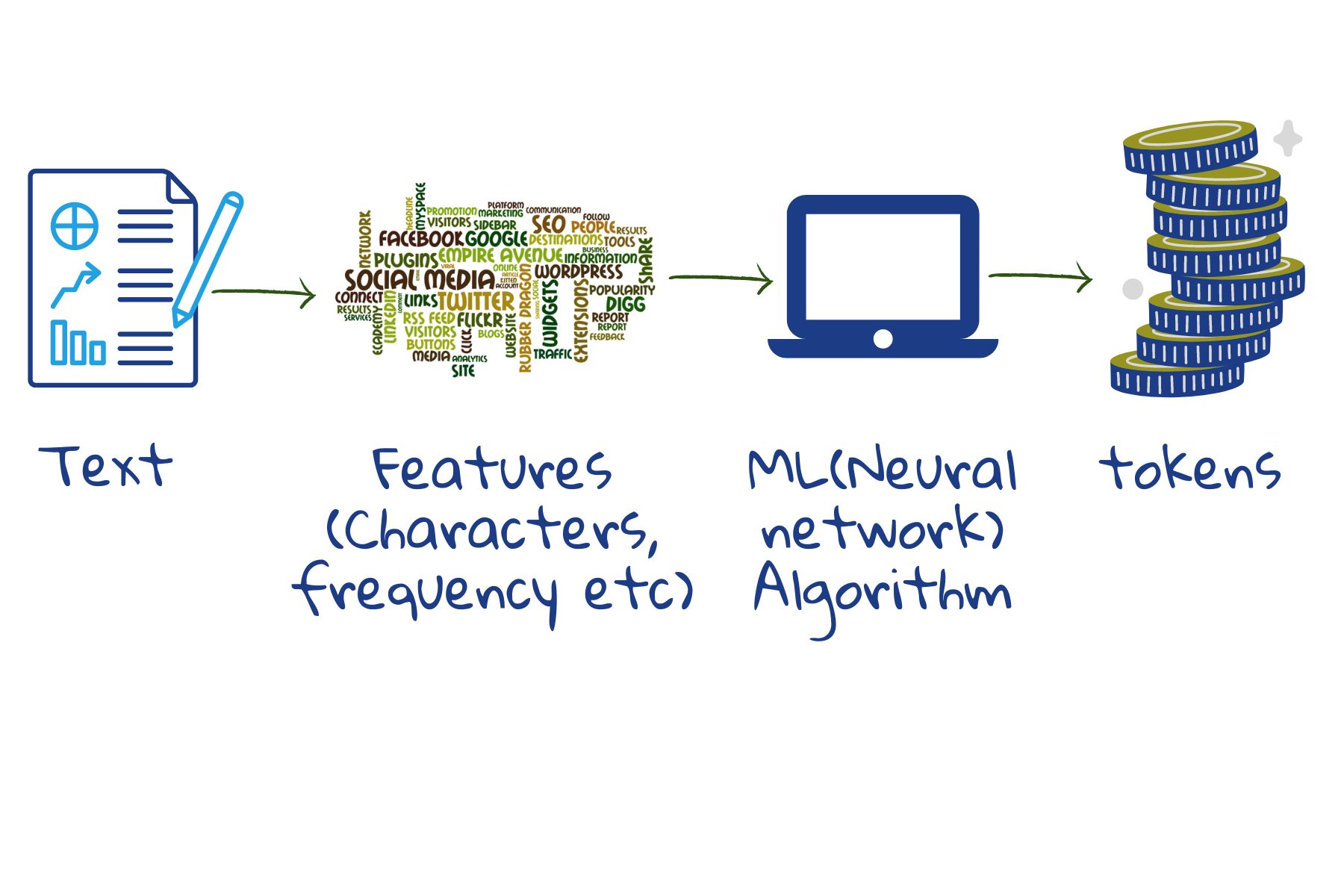
Wenn die programmierende Person die Anwendung erstellt, nimmt sie Daten, extrahiert daraus Merkmale, wählt einen geeigneten Algorithmus für maschinelles Lernen (eine mathematische Funktion, die den Prozess definiert) und trainiert ihn mit markierten Daten (in dem Fall, in dem die Ausgabe bekannt ist - wie Gruppe A oder Gruppe B), so dass die Maschine das Muster hinter dem Problem "versteht".
Für eine Maschine besteht das Verständnis aus einer Reihe von Zahlen - den Gewichten -, die sie jedem Merkmal zuordnet. Durch die richtige Zuordnung der Gewichte kann die Maschine die Wahrscheinlichkeit berechnen, mit der eine neue Karte zur Gruppe A oder zur Gruppe B gehört. In der Regel hilft die programmierende Person der Maschine in der Trainingsphase, indem sie einige Werte manuell ändert - dies wird als Abstimmung (eng.: Tuning) der Anwendung bezeichnet.
Nachdem dies geschehen ist, muss das Programm getestet werden, bevor es in Betrieb genommen werden kann. Zu diesem Zweck werden dem Programm die markierten Daten, die nicht für das Training verwendet wurden, zur Verfügung gestellt. Diese Daten werden als Testdaten bezeichnet. Die Leistung des Programms bei der Vorhersage des Outputs wird dann gemessen. Sobald das Programm als zufriedenstellend eingestuft wird, kann es eingesetzt werden: Es ist bereit, neue Daten zu verarbeiten und eine Entscheidung oder Vorhersage zu treffen.
Die Echtzeitleistung wird dann kontinuierlich überwacht und verbessert (die Gewichtung der Merkmale wird angepasst, um eine bessere Leistung zu erzielen). Häufig führt die Echtzeitleistung zu anderen Ergebnissen, als wenn das maschinelle Lernen mit bereits vorhandenen Daten getestet wird. Da das Experimentieren mit realen Nutzern teuer, zeitaufwändig und oft riskant ist, werden Algorithmen immer mit historischen Nutzerdaten getestet, die möglicherweise nicht in der Lage sind, die Auswirkungen auf das Nutzerverhalten zu ermitteln.1 Daher ist es wichtig, Anwendungen des maschinellen Lernens umfassend zu evaluieren, sobald sie in Betrieb genommen werden:Haben Sie Lust, Machine Learning auszuprobieren? Versuchen Sie diese Aktivität.
------------------------------------------------------------------------------------------------------
1Theobald, O. Machine Learning For Absolute Beginners: A Plain English Introduction (Second Edition) (Machine Learning From Scratch Book 1) (p. 24). Scatterplot Press. Kindle Edition.
2 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021 -
1
2023-01-04T08:48:00+00:00
AI Speak: Wie Youtube über Sie lernt — Teil 2
5
plain
2023-12-29T08:38:11+00:00
Der Prozess
Bei Google werden heute tiefe neuronale Netzwerke für das maschinelle Lernen eingesetzt. 2 Auf der Grundlage des Videomodells nimmt das neuronale Netzwerk von Youtube Videos, die denen ähnlich sind, die die nutzende Person bereits angesehen hat. Dann versucht es, die Verweildauer jedes neuen Videos für eine bestimmte nutzende Person vorherzusagen und ordnet sie auf der Grundlage dieser Vorhersage ein. Die Idee ist dann, die 10 bis 20 Videos (je nach Gerät) mit den besten Platzierungen anzuzeigen.
Der Prozess ähnelt dem Machine-Learning-Modell, das wir zuvor untersucht haben. Zunächst nimmt die Maschine Merkmale aus Benutzer– und Videomodellen, die von der Programmierung vorgegeben werden. Sie lernt aus den Trainingsdaten, welche Gewichtung sie jedem Merkmal geben muss, um die Sehdauer korrekt vorherzusagen. Und dann, wenn sie getestet und für gut befunden wurde, kann sie mit der Vorhersage und Empfehlung beginnen.Schulung
Während des Trainings werden dem System Millionen von positiven und negativen Beispielen vorgelegt. Ein positives Beispiel ist, wenn eine nutzende Person auf ein Video geklickt und es sich eine bestimmte Zeit lang angesehen hat. Ein negatives Beispiel ist, wenn sie nicht auf das Video geklickt hat oder es sich nicht lange angesehen hat.2
Das Netzwerk nimmt die Merkmale einer nutzenden Person und die Videomerkmale auf, die im Abschnitt Modelle in Wie Youtube über Sie lernt — Teil 1 besprochen wurden. Es passt die Wichtigkeit der einzelnen Eingabemerkmale an, indem es prüft, ob es die Sehdauer für ein bestimmtes Video und eine bestimmte nutzende Person korrekt vorhersagt.
Es gibt ungefähr eine Milliarde Parameter (Gewichtung jedes Merkmals), die anhand von Hunderten von Milliarden Beispielen erlernt werden müssen.2 Das Netzwerk kann auch lernen, bestimmte Merkmale zu ignorieren, d.h. ihnen keine Bedeutung beizumessen. So kann die Einbettung oder das Modell, das der Algorithmus erstellt, ganz anders aussehen, als es sich die Entwickelnden vorgestellt haben.Testen
Nachdem das Netzwerk trainiert wurde, wird es an bereits verfügbaren Daten getestet und angepasst. Abgesehen von der Vorhersagegenauigkeit muss die Ausgabe des Systems von den Programmierenden auf der Grundlage mehrerer Werturteile angepasst werden. Die Anzeige von Videos, die den bereits angesehenen Videos zu ähnlich sind, ist nicht sehr ansprechend. Was bedeutet es wirklich, dass eine Empfehlung gut ist? Wie viele ähnliche Videos sollen gezeigt werden und wie viel Abwechslung soll es geben - sowohl in Bezug auf die anderen Videos als auch in Bezug auf den Verlauf der nutzenden Person? Wie viele der Interessen der nutzenden Person sollen abgedeckt werden? Welche Art von Empfehlungen führt zu sofortiger Zufriedenheit und welche zu langfristiger Nutzung?1, 3 Dies sind alles wichtige Fragen, die es zu berücksichtigen gilt.
Nach diesem Test wird eine Echtzeitbewertung der Empfehlungen durchgeführt. Gemessen wird die Gesamtzeit, die eine nutzende Person sich die empfohlenen Videos ansieht.2 Je länger sie sich die empfohlenen Videos ansieht, desto erfolgreicher ist das Modell. Beachten Sie, dass die Anzahl der angeklickten Videos für die Bewertung nicht ausreicht. Youtube bewertet seine Empfehlungsgeber auf der Grundlage der Anzahl der empfohlenen Videos, die zu einem erheblichen Teil angeschaut wurden, der Sitzungsdauer, der Zeit bis zum ersten längeren Anschauen und des Anteils der eingeloggten Nutzenden mit Empfehlungen.1Interface
Schließlich geht es darum, wie die Empfehlungen der betrachtenden Person präsentiert werden: Wie viele Videos sollen gezeigt werden? Sollen die besten Empfehlungen alle auf einmal präsentiert werden, oder sollen einige für später gespeichert werden? 3 Wie sollen Miniaturbilder und Videotitel angezeigt werden? Welche anderen Informationen sollen angezeigt werden? Welche Einstellungen kann die nutzende Person kontrollieren? 1 Die Antworten auf diese Fragen entscheiden darüber, wie Youtube seine zwei Milliarden Nutzerinnen und Nutzer rund um die Uhr zu fesseln vermag.------------------------------------------------------------------------------------------------------
1 Davidson, J., Liebald, B., Liu, J., Nandy, P., Vleet, T., The Youtube Video Recommendation System, Proceedings of the 4th ACM Conference on Recommender Systems, Barcelona, 2010
2 Covington, P., Adams, J., Sargin, E., Deep neural networks for Youtube Recommendations, Proceedings of the 10th ACM Conference on Recommender Systems, ACM, New York, 2016
3 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021
4 Spinelli, L., and Crovella, M., How YouTube Leads Privacy-Seeking Users Away from Reliable Information, In Adjunct Publication of the 28th ACM Conference on User Modeling, Adaptation and Personalization (UMAP '20 Adjunct), Association for Computing Machinery, New York, 244–251, 2020
.jpg){kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
.jpg){kind=link}