Machine learns
1 2023-01-04T08:45:24+00:00 Jotsna Iyer 4f2bfb514a09301de0e5275ee45bf5db41479839 9 1 plain 2023-01-04T08:45:24+00:00 AI for Teachers, An Open Textbook Version 1 English Jotsna Iyer 4f2bfb514a09301de0e5275ee45bf5db41479839This page is referenced by:
-
1
2023-01-04T08:45:24+00:00
Parlare di IA : Come i sistemi adattivi "studiano" lo studente Parte 2
9
plain
2023-06-05T14:27:19+00:00
Il processo
Negli ultimi anni, l'apprendimento automatico è sempre più utilizzato nei sistemi adattivi, come unica tecnologia o in combinazione con altri approcci.2 Quando viene utilizzato, il ruolo principale del ML è quello di creare e aggiornare i modelli degli studenti sulla base di un insieme di caratteristiche, compresi i risultati delle valutazioni e i nuovi dati generati durante il processo.1
Per il ciclo esterno, i modelli vengono creati con l'aiuto dei dati di addestramento, assegnando pesi adeguati alle caratteristiche per aiutare a raccomandare contenuti di apprendimento efficaci.2 (fai riferimento anche a Parlare di IA : Apprendimento automatico). Questi modelli vengono utilizzati per raccomandare regolarmente nuovi percorsi di apprendimento che riflettono i progressi e i cambiamenti di interesse degli studenti, come le nuove raccomandazioni di Youtube. Negli ALS basati su ML, il numero di percorsi può arrivare a trilioni.3
Nel ciclo interno, l'apprendimento automatico viene utilizzato per fornire un feedback adeguato, individuare gli errori, dedurre le lacune nelle conoscenze e valutare la padronanza delle unità di conoscenza (KU). Mentre lavora su un'attività, uno studente potrebbe commettere degli errori. Il ML può essere utilizzato per prevedere quali errori derivano da quali lacune di conoscenza. Se un passaggio della soluzione è corretto, il ML può essere usato per prevedere quali unità di conoscenza sono state padroneggiate con successo.2
Altre tecniche utilizzate nei sistemi adattivi comportano una minore automazione e regole più esplicitamente scritte per fare inferenze.2 Richiedono molto tempo di programmazione e uno sforzo supplementare per catturare accuratamente tutti i criteri che entrano nel processo decisionale. Inoltre, spesso i risultati non possono essere generalizzati da un dominio all'altro o da un problema all'altro.
Gli strumenti che utilizzano il ML utilizzano grandi serie di dati sulle prestazioni effettive degli studenti e sono in grado di creare i percorsi di apprendimento più dinamici per gli studenti nel tempo.1 Come per tutte le applicazioni di ML, è necessario effettuare formazione e test prima di poterle utilizzare in classe.Modello pedagogico
Nel caso di Youtube, abbiamo visto che ci sono molti giudizi di valore su ciò che rende una raccomandazione buona, come ad esempio quanti interessi dell'utente coprire in un set di raccomandazioni, quanti video dovrebbero essere simili a quelli già visti, quanti nuovi contenuti aggiungere per la diversità. (vedi AI Speak : Come Youtube ti studia Parte 2). L'ALS comporta giudizi simili su cosa significhi padroneggiare una KU e su come raggiungere tale padronanza: la pedagogia e l'esperienza quotidiana del discente.4
Nel caso dell'ALS, questi giudizi e indicazioni sul modo in cui uno studente deve progredire dovrebbero essere basati su teorie pedagogiche comprovate. Queste vengono inserite nel modello pedagogico e, insieme ai modelli del dominio e dell'allievo, aiutano la macchina a scegliere un insieme appropriato di attività.
Alcune delle domande che trovano risposta in questo modello sono: Allo studente deve essere presentato un concetto, un'attività o un test? A quale livello di difficoltà? Come valutare l'apprendimento e fornire un feedback? Dove è necessario un maggiore scaffolding? 5 (Con il termine "scaffolding" si fa riferimento a meccanismi di supporto che forniscono indicazioni su concetti e procedure, sulla strategia utilizzata e su come riflettere, pianificare e monitorare l'apprendimento.) Il modello pedagogico determina l'ampiezza e la profondità delle attività e persino la scelta di proseguire all'interno dell'ALS o di farsi aiutare dall'insegnante.3Interfaccia
Le raccomandazioni sono presentate insieme ad altri dati come i progressi, le prestazioni e gli obiettivi degli studenti. Le domande chiave sono:- Come fornire i contenuti?
- Quanti contenuti raccomandare in una sola volta?
- Cosa viene assegnato direttamente e cosa viene raccomandato?
- Quali sono le risorse di supporto?
- È possibile prevedere attività di gruppo?
- Quanta autonomia concedere?
- Lo studente può cambiare le proprie preferenze?
- L'insegnante può modificare i percorsi di apprendimento?
- Quali dati vengono mostrati all'insegnante?
- L'insegnante è coinvolto?
Valutazione
Quando l'ALS viene utilizzato, la maggior parte dei sistemi monitora le proprie prestazioni rispetto ai criteri stabiliti dal programmatore. Come in ogni strumento di intelligenza artificiale, i dati possono essere distorti. Le inferenze tratte dal sistema possono essere imprecise. I dati passati dello studente diventeranno sempre meno rilevanti con il passare del tempo.6 Pertanto, l'insegnante deve anche monitorare le prestazioni del sistema e fornire all'allievo indicazioni e misure correttive, se necessario.
Sono anche gli insegnanti e i compagni che devono fornire ispirazione e rivelare risorse alternative: Per oltre un decennio, la ricerca sui sistemi di raccomandazione è stata orientata dai fornitori di contenuti commerciali e dalle aziende di vendita al dettaglio online. Pertanto, l'attenzione si è concentrata sulla fornitura di raccomandazioni affidabili che producono risultati che possono essere promossi. "Il piacere sorprendente di una gemma inaspettata"7 e le strade meno battute, quelle che possono ispirare fortemente un apprendimento duraturo, non sono un punto di forza dell'apprendimento personalizzato basato sulle macchine.
------------------------------------------------------------------------------------------------------
1 EdSurge, Decoding Adaptive, Pearson, London, 2016
2 Chrysafiadi, K., Virvou, M., Student modeling approaches: A literature review for the last decade, Expert Systems with Applications, Elseiver, 2013
3 Essa, A., A possible future for next generation adaptive learning systems, Smart Learning Environments, 3, 16, 2016
4 Groff, J., Personalized Learning : The state of the field and future directions, Center for curriculum redesign, 2017.
5 Alkhatlan, A., Kalita, J.K., Intelligent Tutoring Systems: A Comprehensive Historical Survey with Recent Developments, International Journal of Computer Applications 181(43):1-20, March 2019
6 du Boulay, B., Poulovasillis, A., Holmes, W., Mavrikis, M., Artificial Intelligence And Big Data Technologies To Close The Achievement Gap, In: Luckin, Rose ed. Enhancing Learning and Teaching with Technology. London: UCL Institute of Education Press, pp. 256–28, 2018
7 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021
-
1
2023-01-04T08:45:24+00:00
Parlare di IA : Come Youtube ti studia Parte 2
8
plain
2023-06-05T14:26:29+00:00
Il processo
In Google, le reti neurali profonde vengono ora utilizzate per l'apprendimento automatico.2 In base al modello di video, la rete neurale di Youtube prende i video simili a quelli già visti dall'utente. Poi cerca di prevedere il tempo di visione di ogni nuovo video per un determinato modello di utente e li classifica in base alla previsione. L'idea è quella di mostrare i 10-20 video (a seconda del dispositivo) con la migliore posizione in classifica.
Il processo è simile a quello del Machine Learning model che abbiamo studiato in precedenza. In primo luogo, la macchina prende le caratteristiche dai modelli di utenti e video forniti dal programmatore. Impara dai dati di addestramento quale peso dare a ciascuna caratteristica per prevedere correttamente il tempo di visione. Poi, una volta testata e trovata corretta, può iniziare a prevedere e consigliare.Training
Durante l'addestramento, il sistema riceve milioni di esempi positivi e negativi. Un esempio positivo si ha quando un utente clicca su un video e lo guarda per un certo tempo. Un esempio negativo è quando l'utente non clicca sul video o non lo guarda a lungo.2
La rete prende in considerazione le caratteristiche dell'utente e le caratteristiche del video discusse nella sezione modelli di Come Youtube vi studia Parte 1. Regola l'importanza data a ciascuna caratteristica di input verificando se ha previsto correttamente il tempo di visione per un determinato video e utente.
Ci sono circa un miliardo di parametri (peso di ogni caratteristica) da apprendere su centinaia di miliardi di esempi.2 La rete potrebbe anche imparare a non tenere conto di alcune caratteristiche, attribuendo loro un'importanza pari a zero. Pertanto, l'incorporazione o il modello creato dall'algoritmo può essere molto diverso da quello previsto dagli sviluppatori.Testing
Una volta addestrata, la rete viene testata su dati già disponibili e regolata. Oltre all'accuratezza della previsione, l'output del sistema deve essere regolato dal programmatore in base a diversi giudizi di valore. Mostrare video troppo simili a quelli già visti non sarà molto coinvolgente. Cosa significa veramente che una raccomandazione è buona? Quanti video simili mostrare e quanta diversità introdurre, sia rispetto agli altri video sia rispetto alla storia dell'utente. Quanti interessi dell'utente coprire? Quali tipi di raccomandazioni portano a una soddisfazione immediata e quali a un utilizzo a lungo termine?1,3 Sono tutte domande importanti da considerare.
Dopo questo test, si procede alla valutazione in tempo reale delle raccomandazioni. Viene misurato il tempo totale di visione per ogni serie di video predetti.2 Se un utente guarda più a lungo l'insieme di video raccomandati, il modello è considerato di maggior successo. Si noti che la semplice osservazione del numero di video cliccati non è un buon metodo di valutazione. Youtube valuta i suoi raccomandatori in base a quanti video raccomandati sono stati guardati per una frazione sostanziale del video, alla durata della sessione, al tempo trascorso fino alla prima visione prolungata e alla frazione di utenti connessi con raccomandazioni.1Interfaccia
Infine, il modo in cui le raccomandazioni vengono presentate allo spettatore: quanti video mostrare? Le raccomandazioni migliori devono essere presentate tutte insieme o alcune devono essere conservate per un secondo momento? 3 Come visualizzare le miniature e i titoli dei video? Quali altre informazioni mostrare? Quali impostazioni può controllare l'utente?1 Le risposte a queste domande determinano il modo in cui Youtube tiene agganciati due miliardi di utenti 24 ore al giorno.------------------------------------------------------------------------------------------------------
1 Davidson, J., Liebald, B., Liu, J., Nandy, P., Vleet, T., The Youtube Video Recommendation System, Proceedings of the 4th ACM Conference on Recommender Systems, Barcelona, 2010
2 Covington, P., Adams, J., Sargin, E., Deep neural networks for Youtube Recommendations, Proceedings of the 10th ACM Conference on Recommender Systems, ACM, New York, 2016
3 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021
4 Spinelli, L., and Crovella, M., How YouTube Leads Privacy-Seeking Users Away from Reliable Information, In Adjunct Publication of the 28th ACM Conference on User Modeling, Adaptation and Personalization (UMAP '20 Adjunct), Association for Computing Machinery, New York, 244–251, 2020 -
1
2023-01-04T08:45:24+00:00
Parlare di IA : Apprendimento automatico
4
plain
2023-05-29T13:32:05+00:00
Un algoritmo è una sequenza fissa di istruzioni per svolgere un compito. Il compito è suddiviso in fasi facili e prive di confusione: come una ricetta ben scritta.
I linguaggi di programmazione sono linguaggi che un computer può seguire ed eseguire. Fanno da ponte tra ciò che capiamo e ciò che può fare una macchina - in definitiva, interruttori che si accendono e si spengono. Per un computer immagini, video, istruzioni sono tutti degli 1 (interruttore acceso) e degli 0 (interruttore spento).
Quando viene scritto in un linguaggio di programmazione, un algoritmo diventa un programma. Le applicazioni sono programmi scritti per un utente finale.
I programmi convenzionali ricevono i dati e seguono le istruzioni per fornire un risultato. Molti dei primi programmi di intelligenza artificiale erano convenzionali. Poiché le istruzioni non possono adattarsi ai dati, questi programmi non erano molto bravi in cose come la previsione basata su informazioni incomplete e l'elaborazione del linguaggio naturale (NLP).
Un motore di ricerca è alimentato sia da fonti convenzionali che da algoritmi di apprendimento automatico. A differenza dei programmi convenzionali, gli algoritmi di apprendimento automatico analizzano i dati alla ricerca di modelli e utilizzano questi modelli o regole per prendere decisioni o previsioni future. In altre parole, basandosi sui dati - esempi buoni e cattivi - trovano la loro ricetta.
Questi algoritmi sono adatti a situazioni molto complesse e con dati mancanti. Possono anche monitorare le loro prestazioni e utilizzare questo feedback per migliorare con l'uso.
Questo non è molto diverso dagli esseri umani, in particolare dai bambini, che apprendono abilità al di fuori del sistema educativo convenzionale. I bambini osservano, ripetono, imparano, verificano il loro apprendimento e migliorano. Se necessario, improvvisano.
Ma la somiglianza tra macchine e umani è molto superficiale. L'"apprendimento" dal punto di vista umano è molto diverso e molto più sfumato e complesso dell'"apprendimento" per la macchina.Un problema di classificazione
Un compito comune che un'applicazione di apprendimento automatico adotta per il suo funzionamento è la classificazione: questa è la foto di un cane o di un gatto? Questo studente è in difficoltà o ha superato l'esame? Esistono due o più gruppi. L'applicazione deve classificare i nuovi dati in uno di questi gruppi.
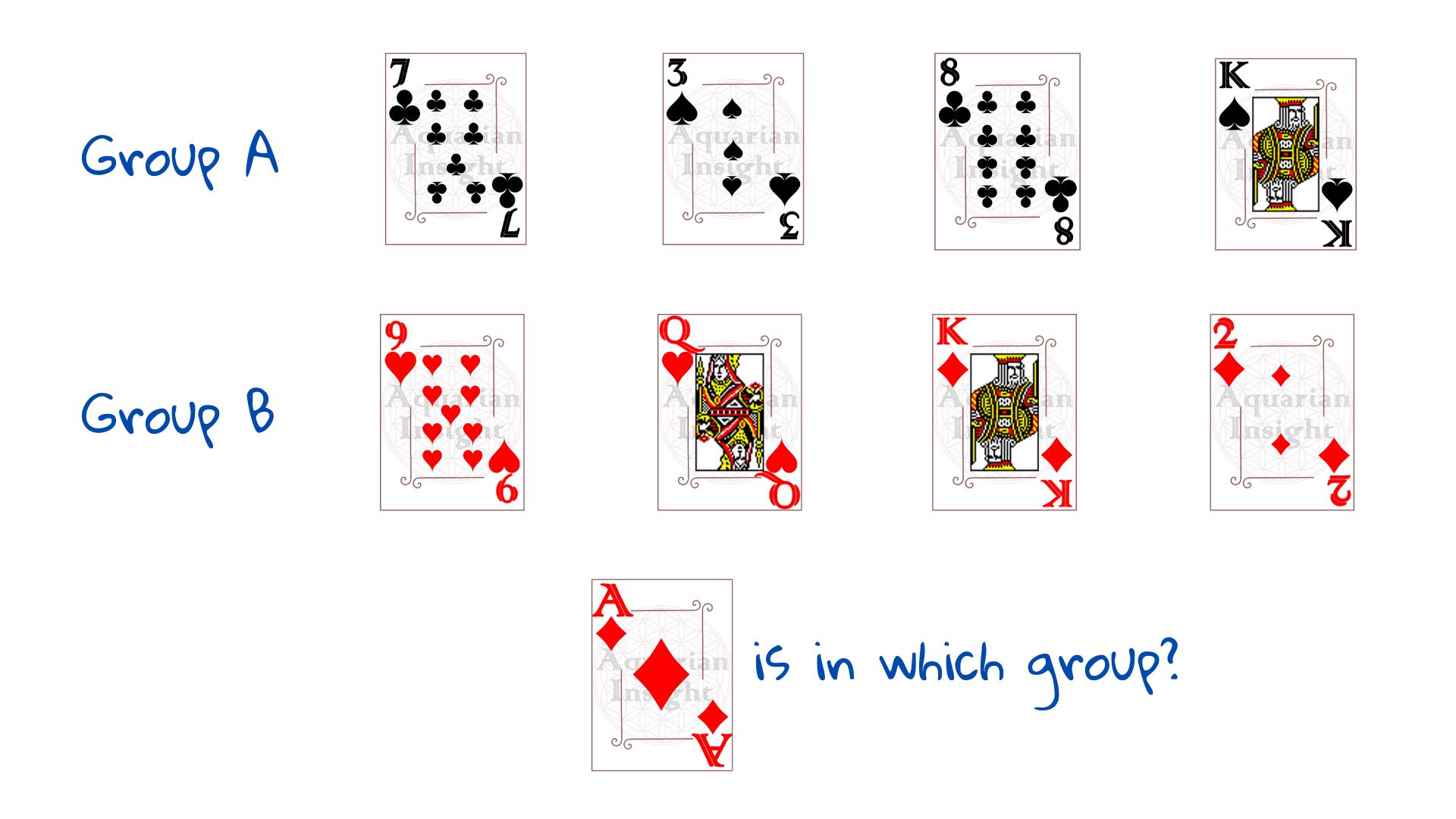
Prendiamo l'esempio di un mazzo di carte da gioco diviso in due pile - Gruppo A e Gruppo B, secondo un certo schema. Dobbiamo classificare una nuova carta, l'asso di quadri, come appartenente al Gruppo A o al Gruppo B.
Per prima cosa, dobbiamo capire come vengono suddivisi i gruppi: abbiamo bisogno di esempi. Pesciamo quattro carte dal gruppo A e quattro dal gruppo B. Questi 8 casi di esempio formano il nostro insieme di addestramento - dati che ci aiutano a vedere il modello - "allenandoci" a vedere il risultato.
Non appena ci viene mostrata la disposizione a destra, la maggior parte di noi indovina che l'Asso di quadri appartiene al gruppo B. Non abbiamo bisogno di istruzioni, il cervello umano è un prodigio nel trovare schemi. Come farebbe una macchina a farlo?
Gli algoritmi di apprendimento automatico si basano su potenti teorie statistiche. I diversi algoritmi si basano su equazioni matematiche diverse che devono essere scelte con attenzione per adattarsi al compito da svolgere. È compito del programmatore scegliere i dati, analizzare quali caratteristiche dei dati sono rilevanti per il problema specifico e scegliere l'algoritmo di apprendimento automatico corretto.L'importanza dei dati
L'estrazione della carta qui sopra potrebbe essere andata male in diversi modi. Fare riferimento all'immagine. 1 ha troppe poche carte, non è possibile indovinare. Il 2 ha più carte, ma tutte dello stesso seme: non c'è modo di sapere dove andrebbero i diamanti. Se i gruppi non sono della stessa dimensione, il 3 potrebbe benissimo significare che le carte numero sono nel gruppo A e le carte immagine nel gruppo B.
Di solito i problemi di apprendimento automatico sono più aperti e coinvolgono insiemi di dati molto più grandi di un mazzo di carte. Gli insiemi di addestramento devono essere scelti con l'aiuto dell'analisi statistica, altrimenti gli errori si insinuano. Una buona selezione dei dati è fondamentale per una buona applicazione di ML, più di altri tipi di programmi. L'apprendimento automatico ha bisogno di un gran numero di dati rilevanti. Come minimo assoluto, un modello di apprendimento automatico di base dovrebbe contenere un numero di punti dati dieci volte superiore al numero totale di caratteristiche.1 Detto questo, il ML è anche particolarmente adatto a gestire dati rumorosi, disordinati e contraddittori.
Quando sono stati mostrati gli esempi del Gruppo A e del Gruppo B, la prima cosa che avete notato potrebbe essere il colore delle carte. Poi il numero o la lettera e il seme. Per un algoritmo tutte queste caratteristiche devono essere inserite in modo specifico. Non può sapere automaticamente cosa è importante per il problema.
Estrazione delle caratteristiche
Nel selezionare le caratteristiche di interesse, i programmatori devono porsi molte domande. Quante funzioni sono troppo poche per essere utili? Quante caratteristiche sono troppe? Quali caratteristiche sono rilevanti per il compito? Qual è la relazione tra le caratteristiche scelte - una caratteristica dipende dall'altra? Con le caratteristiche scelte, è possibile che l'output sia accurato?Il processo
Quando il programmatore crea l'applicazione, prende i dati, ne estrae le caratteristiche, sceglie un algoritmo di apprendimento automatico appropriato (funzione matematica che definisce il processo) e lo addestra utilizzando dati etichettati (nel caso in cui l'output sia noto, come il gruppo A o il gruppo B) in modo che la macchina capisca il modello alla base del problema.
Per una macchina la comprensione assume la forma di un insieme di numeri - i pesi - che essa assegna a ciascuna caratteristica. Con l'assegnazione corretta dei pesi, la macchina può calcolare la probabilità che una nuova tessera appartenga al gruppo A o al gruppo B. In genere, durante la fase di addestramento, il programmatore aiuta la macchina modificando manualmente alcuni valori: questa operazione si chiama ottimizzazione dell'applicazione.
Una volta fatto questo, il programma deve essere testato prima di essere utilizzato. A tale scopo, al programma vengono forniti i dati etichettati che non sono stati utilizzati per l'addestramento. Questi dati sono chiamati dati di prova. A questo punto si valutano le prestazioni della macchina nel predire l'output. Una volta stabilito che le prestazioni sono soddisfacenti, il programma può essere messo in uso: è pronto a prendere nuovi dati e a fare una decisione o una previsione su di essi.
Le prestazioni in tempo reale vengono poi continuamente monitorate e migliorate (i pesi delle caratteristiche vengono aggiustati per ottenere risultati migliori). Spesso, le prestazioni in tempo reale danno risultati diversi rispetto a quando l'algoritmo di apprendimento automatico viene testato con dati già disponibili. Poiché sperimentare con utenti reali è costoso, richiede un elevato sforzo e spesso è rischioso, gli algoritmi vengono sempre testati utilizzando dati storici degli utenti, che potrebbero non essere in grado di valutare l'impatto sul comportamento degli utenti.1 Per questo motivo è importante effettuare una valutazione completa delle applicazioni di apprendimento automatico una volta in uso:
Avete voglia di mettere mano all'apprendimento automatico? Provate questa attività.
------------------------------------------------------------------------------------------------------
1Theobald, O. Machine Learning For Absolute Beginners: A Plain English Introduction (Second Edition) (Machine Learning From Scratch Book 1) (p. 24). Scatterplot Press. Kindle Edition.
2 Konstan, J., Terveen, L., Human-centered recommender systems: Origins, advances, challenges, and opportunities, AI Magazine, 42(3), 31-42, 2021
{kind=link}
.jpg){kind=link}
{kind=link}
.jpg){kind=link}
.jpg){kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
.jpg){kind=link}